This is the multi-page printable view of this section. Click here to print.
Documentation
- 1: Getting started
- 1.1: Introduction to Kubernetes operators
- 1.2: Bootstrapping and samples
- 1.3: Patterns and best practices
- 2: Documentation
- 2.1: Implementing a reconciler
- 2.2: Error handling and retries
- 2.3: Event sources and related topics
- 2.4: Working with EventSource caches
- 2.5: Configurations
- 2.6: Observability
- 2.7: Other Features
- 2.8: Dependent resources and workflows
- 2.8.1: Dependent resources
- 2.8.2: Workflows
- 2.9: Architecture and Internals
- 3: Integration Test Index
- 4: FAQ
- 5: Glossary
- 6: Contributing
- 7: Migrations
1 - Getting started
1.1 - Introduction to Kubernetes operators
What are Kubernetes Operators?
Kubernetes operators are software extensions that manage both cluster and non-cluster resources on behalf of Kubernetes. The Java Operator SDK (JOSDK) makes it easy to implement Kubernetes operators in Java, with APIs designed to feel natural to Java developers and framework handling of common problems so you can focus on your business logic.
Why Use Java Operator SDK?
JOSDK provides several key advantages:
- Java-native APIs that feel familiar to Java developers
- Automatic handling of common operator challenges (caching, event handling, retries)
- Production-ready features like observability, metrics, and error handling
- Simplified development so you can focus on business logic instead of Kubernetes complexities
Learning Resources
Getting Started
- Introduction to Kubernetes operators - Core concepts explained
- Implementing Kubernetes Operators in Java - Introduction talk
- Kubernetes operator pattern documentation - Official Kubernetes docs
Deep Dives
- Problems JOSDK solves - Technical deep dive
- Why Java operators make sense - Java in cloud-native infrastructure
- Building a Kubernetes operator SDK for Java - Framework design principles
Tutorials
- Writing Kubernetes operators using JOSDK - Step-by-step blog series
1.2 - Bootstrapping and samples
Creating a New Operator Project
Using the Maven Plugin
The simplest way to start a new operator project is using the provided Maven plugin, which generates a complete project skeleton:
mvn io.javaoperatorsdk:bootstrapper:[version]:create \
-DprojectGroupId=org.acme \
-DprojectArtifactId=getting-started
This command creates a new Maven project with:
- A basic operator implementation
- Maven configuration with required dependencies
- Generated CustomResourceDefinition (CRD)
Building Your Project
Build the generated project with Maven:
mvn clean install
The build process automatically generates the CustomResourceDefinition YAML file that you’ll need to apply to your Kubernetes cluster.
Exploring Sample Operators
The sample-operators directory contains real-world examples demonstrating different JOSDK features and patterns:
Available Samples
- Purpose: Creates NGINX webservers from Custom Resources containing HTML code
- Key Features: Multiple implementation approaches using both low-level APIs and higher-level abstractions
- Good for: Understanding basic operator concepts and API usage patterns
- Purpose: Manages database schemas in MySQL instances
- Key Features: Demonstrates managing non-Kubernetes resources (external systems)
- Good for: Learning how to integrate with external services and manage state outside Kubernetes
- Purpose: Manages Tomcat instances and web applications
- Key Features: Multiple controllers managing related custom resources
- Good for: Understanding complex operators with multiple resource types and relationships
Running the Samples
Prerequisites
The easiest way to try samples is using a local Kubernetes cluster:
Step-by-Step Instructions
Apply the CustomResourceDefinition:
kubectl apply -f target/classes/META-INF/fabric8/[resource-name]-v1.ymlRun the operator:
mvn exec:java -Dexec.mainClass="your.main.ClassName"Or run your main class directly from your IDE.
Create custom resources: The operator will automatically detect and reconcile custom resources when you create them:
kubectl apply -f examples/sample-resource.yaml
Detailed Examples
For comprehensive setup instructions and examples, see:
- MySQL Schema sample README
- Individual sample directories for specific setup requirements
Next Steps
After exploring the samples:
- Review the patterns and best practices guide
- Learn about implementing reconcilers
- Explore dependent resources and workflows for advanced use cases
1.3 - Patterns and best practices
This document describes patterns and best practices for building and running operators, and how to implement them using the Java Operator SDK (JOSDK).
See also best practices in the Operator SDK.
Implementing a Reconciler
Always Reconcile All Resources
Reconciliation can be triggered by events from multiple sources. It might be tempting to check the events and only reconcile the related resource or subset of resources that the controller manages. However, this is considered an anti-pattern for operators.
Why this is problematic:
- Kubernetes’ distributed nature makes it difficult to ensure all events are received
- If your operator misses some events and doesn’t reconcile the complete state, it might operate with incorrect assumptions about the cluster state
- Always reconcile all resources, regardless of the triggering event
JOSDK makes this efficient by providing smart caches to avoid unnecessary Kubernetes API server access and ensuring your reconciler is triggered only when needed.
Since there’s industry consensus on this topic, JOSDK no longer provides event access from Reconciler implementations starting with version 2.
Event Sources and Caching
During reconciliation, best practice is to reconcile all dependent resources managed by the controller. This means comparing the desired state with the actual cluster state.
The Challenge: Reading the actual state directly from the Kubernetes API Server every time would create significant load.
The Solution: Create a watch for dependent resources and cache their latest state using the Informer pattern. In JOSDK, informers are wrapped into EventSource to integrate with the framework’s eventing system via the InformerEventSource class.
How it works:
- New events trigger reconciliation only when the resource is already cached
- Reconciler implementations compare desired state with cached observed state
- If a resource isn’t in cache, it needs to be created
- If actual state doesn’t match desired state, the resource needs updating
Idempotency
Since all resources should be reconciled when your Reconciler is triggered, and reconciliations can be triggered multiple times for any given resource (especially with retry policies), it’s crucial that Reconciler implementations be idempotent.
Idempotency means: The same observed state should always result in exactly the same outcome.
Key implications:
- Operators should generally operate in a stateless fashion
- Since operators usually manage declarative resources, ensuring idempotency is typically straightforward
Synchronous vs Asynchronous Resource Handling
Sometimes your reconciliation logic needs to wait for resources to reach their desired state (e.g., waiting for a Pod to become ready). You can approach this either synchronously or asynchronously.
Asynchronous Approach (Recommended)
Exit the reconciliation logic as soon as the Reconciler determines it cannot complete at this point. This frees resources to process other events.
Requirements: Set up adequate event sources to monitor state changes of all resources the operator waits for. When state changes occur, the Reconciler is triggered again and can finish processing.
Synchronous Approach
Periodically poll resources’ state until they reach the desired state. If done within the reconcile method, this blocks the current thread for potentially long periods.
Recommendation: Use the asynchronous approach for better resource utilization.
Why Use Automatic Retries?
Automatic retries are enabled by default and configurable. While you can deactivate this feature, we advise against it.
Why retries are important:
- Transient network errors: Common in Kubernetes’ distributed environment, easily resolved with retries
- Resource conflicts: When multiple actors modify resources simultaneously, conflicts can be resolved by reconciling again
- Transparency: Automatic retries make error handling completely transparent when successful
Managing State
Thanks to Kubernetes resources’ declarative nature, operators dealing only with Kubernetes resources can operate statelessly. They don’t need to maintain resource state information since it should be possible to rebuild the complete resource state from its representation.
When State Management Becomes Necessary
This stateless approach typically breaks down when dealing with external resources. You might need to track external state or allocated values for future reconciliations. There are multiple options:
Putting state in the primary resource’s status sub-resource. This is a bit more complex that might seem at the first look. Refer to the documentation for further details.
Store state in separate resources designed for this purpose:
- Kubernetes Secret or ConfigMap
- Dedicated Custom Resource with validated structure
Handling Informer Errors and Cache Sync Timeouts
You can configure whether the operator should stop when informer errors occur on startup.
Default Behavior
By default, if there’s a startup error (e.g., the informer lacks permissions to list target resources for primary or secondary resources), the operator stops immediately.
Alternative Configuration
Set the flag to false to start the operator even when some informers fail to start. In this case:
- The operator continuously retries connection with exponential backoff
- This applies both to startup failures and runtime problems
- The operator only stops for fatal errors (currently when a resource cannot be deserialized)
Use case: When watching multiple namespaces, it’s better to start the operator so it can handle other namespaces while resolving permission issues in specific namespaces.
Cache Sync Timeout Impact
The stopOnInformerErrorDuringStartup setting affects cache sync timeout behavior:
- If
true: Operator stops on cache sync timeout - If
false: After timeout, the controller starts reconciling resources even if some event source caches haven’t synced yet
Graceful Shutdown
You can provide sufficient time for the reconciler to process and complete ongoing events before shutting down. Simply set an appropriate duration value for reconciliationTerminationTimeout using ConfigurationServiceOverrider.
final var operator = new Operator(override -> override.withReconciliationTerminationTimeout(Duration.ofSeconds(5)));
2 - Documentation
JOSDK Documentation
This section contains detailed documentation for all Java Operator SDK features and concepts. Whether you’re building your first operator or need advanced configuration options, you’ll find comprehensive guides here.
Core Concepts
- Implementing a Reconciler - The heart of any operator
- Architecture - How JOSDK works under the hood
- Dependent Resources & Workflows - Managing resource relationships
- Configuration - Customizing operator behavior
- Error Handling & Retries - Managing failures gracefully
Advanced Features
- Eventing - Understanding the event-driven model
- Accessing Resources in Caches - How to access resources in caches
- Observability - Monitoring and debugging your operators
- Other Features - Additional capabilities and integrations
Each guide includes practical examples and best practices to help you build robust, production-ready operators.
2.1 - Implementing a reconciler
How Reconciliation Works
The reconciliation process is event-driven and follows this flow:
Event Reception: Events trigger reconciliation from:
- Primary resources (usually custom resources) when created, updated, or deleted
- Secondary resources through registered event sources
Reconciliation Execution: Each reconciler handles a specific resource type and listens for events from the Kubernetes API server. When an event arrives, it triggers reconciliation unless one is already running for that resource. The framework ensures no concurrent reconciliation occurs for the same resource.
Post-Reconciliation Processing: After reconciliation completes, the framework:
- Schedules a retry if an exception was thrown
- Schedules new reconciliation if events were received during execution
- Schedules a timer event if rescheduling was requested (
UpdateControl.rescheduleAfter(..)) - Finishes reconciliation if none of the above apply
The SDK core implements an event-driven system where events trigger reconciliation requests.
Implementing Reconciler and Cleaner Interfaces
To implement a reconciler, you must implement the Reconciler interface.
A Kubernetes resource lifecycle has two phases depending on whether the resource is marked for deletion:
Normal Phase: The framework calls the reconcile method for regular resource operations.
Deletion Phase: If the resource is marked for deletion and your Reconciler implements the Cleaner interface, only the cleanup method is called. The framework automatically handles finalizers for you.
If you need explicit cleanup logic, always use finalizers. See Finalizer support for details.
Using UpdateControl and DeleteControl
These classes control the behavior after reconciliation completes.
UpdateControl can instruct the framework to:
- Update the status sub-resource
- Reschedule reconciliation with a time delay
@Override
public UpdateControl<MyCustomResource> reconcile(
EventSourceTestCustomResource resource, Context context) {
// omitted code
return UpdateControl.patchStatus(resource).rescheduleAfter(10, TimeUnit.SECONDS);
}
without an update:
@Override
public UpdateControl<MyCustomResource> reconcile(
EventSourceTestCustomResource resource, Context context) {
// omitted code
return UpdateControl.<MyCustomResource>noUpdate().rescheduleAfter(10, TimeUnit.SECONDS);
}
Note, though, that using EventSources is the preferred way of scheduling since the
reconciliation is triggered only when a resource is changed, not on a timely basis.
At the end of the reconciliation, you typically update the status sub-resources.
It is also possible to update both the status and the resource with the patchResourceAndStatus method. In this case,
the resource is updated first followed by the status, using two separate requests to the Kubernetes API.
From v5 UpdateControl only supports patching the resources, by default
using Server Side Apply (SSA).
It is important to understand how SSA works in Kubernetes. Mainly, resources applied using SSA
should contain only the fields identifying the resource and those the user is interested in (a ‘fully specified intent’
in Kubernetes parlance), thus usually using a resource created from scratch, see
sample.
To contrast, see the same sample, this time without SSA.
Non-SSA based patch is still supported.
You can control whether or not to use SSA
using ConfigurationServcice.useSSAToPatchPrimaryResource()
and the related ConfigurationServiceOverrider.withUseSSAToPatchPrimaryResource method.
Related integration test can be
found here.
Handling resources directly using the client, instead of delegating these updates operations to JOSDK by returning
an UpdateControl at the end of your reconciliation, should work appropriately. However, we do recommend to
use UpdateControl instead since JOSDK makes sure that the operations are handled properly, since there are subtleties
to be aware of. For example, if you are using a finalizer, JOSDK makes sure to include it in your fully specified intent
so that it is not unintentionally removed from the resource (which would happen if you omit it, since your controller is
the designated manager for that field and Kubernetes interprets the finalizer being gone from the specified intent as a
request for removal).
DeleteControl
typically instructs the framework to remove the finalizer after the dependent
resource are cleaned up in cleanup implementation.
public DeleteControl cleanup(MyCustomResource customResource,Context context){
// omitted code
return DeleteControl.defaultDelete();
}
However, it is possible to instruct the SDK to not remove the finalizer, this allows to clean up
the resources in a more asynchronous way, mostly for cases when there is a long waiting period
after a delete operation is initiated. Note that in this case you might want to either schedule
a timed event to make sure cleanup is executed again or use event sources to get notified
about the state changes of the deleted resource.
Finalizer Support
Kubernetes finalizers
make sure that your Reconciler gets a chance to act before a resource is actually deleted
after it’s been marked for deletion. Without finalizers, the resource would be deleted directly
by the Kubernetes server.
Depending on your use case, you might or might not need to use finalizers. In particular, if
your operator doesn’t need to clean any state that would not be automatically managed by the
Kubernetes cluster (e.g. external resources), you might not need to use finalizers. You should
use the
Kubernetes garbage collection
mechanism as much as possible by setting owner references for your secondary resources so that
the cluster can automatically delete them for you whenever the associated primary resource is
deleted. Note that setting owner references is the responsibility of the Reconciler
implementation, though dependent resources
make that process easier.
If you do need to clean such a state, you need to use finalizers so that their presence will prevent the Kubernetes server from deleting the resource before your operator is ready to allow it. This allows for clean-up even if your operator was down when the resource was marked for deletion.
JOSDK makes cleaning resources in this fashion easier by taking care of managing finalizers
automatically for you when needed. The only thing you need to do is let the SDK know that your
operator is interested in cleaning the state associated with your primary resources by having it
implement
the Cleaner<P>
interface. If your Reconciler doesn’t implement the Cleaner interface, the SDK will consider
that you don’t need to perform any clean-up when resources are deleted and will, therefore, not activate finalizer support.
In other words, finalizer support is added only if your Reconciler implements the Cleaner interface.
The framework automatically adds finalizers as the first step, thus after a resource is created but before the first reconciliation. The finalizer is added via a separate Kubernetes API call. As a result of this update, the finalizer will then be present on the resource. The reconciliation can then proceed as normal.
The automatically added finalizer will also be removed after the cleanup is executed on
the reconciler. This behavior is customizable as explained
above when we addressed the use of
DeleteControl.
You can specify the name of the finalizer to use for your Reconciler using the
@ControllerConfiguration
annotation. If you do not specify a finalizer name, one will be automatically generated for you.
From v5, by default, the finalizer is added using Server Side Apply. See also UpdateControl in docs.
Making sure the primary resource is up to date for the next reconciliation
It is typical to want to update the status subresource with the information that is available during the reconciliation. This is sometimes referred to as the last observed state. When the primary resource is updated, though, the framework does not cache the resource directly, relying instead on the propagation of the update to the underlying informer’s cache. It can, therefore, happen that, if other events trigger other reconciliations, before the informer cache gets updated, your reconciler does not see the latest version of the primary resource. While this might not typically be a problem in most cases, as caches eventually become consistent, depending on your reconciliation logic, you might still require the latest status version possible, for example, if the status subresource is used to store allocated values. See Representing Allocated Values from the Kubernetes docs for more details.
The framework provides thePrimaryUpdateAndCacheUtils utility class
to help with these use cases.
This class’ methods use internal caches in combination with update methods that leveraging optimistic locking. If the update method fails on optimistic locking, it will retry using a fresh resource from the server as base for modification.
@Override
public UpdateControl<StatusPatchCacheCustomResource> reconcile(
StatusPatchCacheCustomResource resource, Context<StatusPatchCacheCustomResource> context) {
// omitted logic
// update with SSA requires a fresh copy
var freshCopy = createFreshCopy(primary);
freshCopy.getStatus().setValue(statusWithState());
var updatedResource = PrimaryUpdateAndCacheUtils.ssaPatchStatusAndCacheResource(resource, freshCopy, context);
// the resource was updated transparently via the utils, no further action is required via UpdateControl in this case
return UpdateControl.noUpdate();
}
After the update PrimaryUpdateAndCacheUtils.ssaPatchStatusAndCacheResource puts the result of the update into an internal
cache and the framework will make sure that the next reconciliation contains the most recent version of the resource.
Note that it is not necessarily the same version returned as response from the update, it can be a newer version since other parties
can do additional updates meanwhile. However, unless it has been explicitly modified, that
resource will contain the up-to-date status.
Note that you can also perform additional updates after the PrimaryUpdateAndCacheUtils.*PatchStatusAndCacheResource is
called, either by calling any of the PrimeUpdateAndCacheUtils methods again or via UpdateControl. Using
PrimaryUpdateAndCacheUtils guarantees that the next reconciliation will see a resource state no older than the version
updated via PrimaryUpdateAndCacheUtils.
See related integration test here.
Trigger reconciliation for all events
TLDR; We provide an execution mode where reconcile method is called on every event from event source.
The framework optimizes execution for generic use cases, which, in almost all cases, fall into two categories:
- The controller does not use finalizers; thus when the primary resource is deleted, all the managed secondary resources are cleaned up using the Kubernetes garbage collection mechanism, a.k.a., using owner references. This mechanism, however, only works when all secondary resources are Kubernetes resources in the same namespace as the primary resource.
- The controller uses finalizers (the controller implements the
Cleanerinterface), when explicit cleanup logic is required, typically for external resources and when secondary resources are in different namespace than the primary resources (owner references cannot be used in this case).
Note that neither of those cases trigger the reconcile method of the controller on the Delete event of the primary
resource. When a finalizer is used, the SDK calls the cleanup method of the Cleaner implementation when the resource
is marked for deletion and the finalizer specified by the controller is present on the primary resource. When there is
no finalizer, there is no need to call the reconcile method on a Delete event since all the cleanup will be done by
the garbage collector. This avoids reconciliation cycles.
However, there are cases when controllers do not strictly follow those patterns, typically when:
- Only some of the primary resources use finalizers, e.g., for some of the primary resources you need to create an external resource for others not.
- You maintain some additional in memory caches (so not all the caches are encapsulated by an
EventSource) and you don’t want to use finalizers. For those cases, you typically want to clean up your caches when the primary resource is deleted.
For such use cases you can set triggerReconcilerOnAllEvents
to true, as a result, the reconcile method will be triggered on ALL events (so also Delete events), making it
possible to support the above use cases.
In this mode:
- even if the primary resource is already deleted from the Informer’s cache, we will still pass the last known state
as the parameter for the reconciler. You can check if the resource is deleted using
Context.isPrimaryResourceDeleted(). - The retry, rate limiting, re-schedule, filters mechanisms work normally. The internal caches related to the resource
are cleaned up only when there is a successful reconciliation after a
Deleteevent was received for the primary resource and reconciliation is not re-scheduled. - you cannot use the
Cleanerinterface. The framework assumes you will explicitly manage the finalizers. To add finalizer you can usePrimeUpdateAndCacheUtils. - you cannot use managed dependent resources since those manage the finalizers and other logic related to the normal execution mode.
See also sample for selectively adding finalizers for resources;
Expectations
Expectations are a pattern to ensure that, during reconciliation, your secondary resources are in a certain state.
For a more detailed explanation see this blogpost.
You can find framework support for this pattern in io.javaoperatorsdk.operator.processing.expectation
package. See also related integration test.
Note that this feature is marked as @Experimental, since based on feedback the API might be improved / changed, but we intend
to support it, later also might be integrated to Dependent Resources and/or Workflows.
The idea is the nutshell, is that you can track your expectations in the expectation manager in the reconciler which has an API that covers the common use cases.
The following sample is the simplified version of the integration test that implements the logic that creates a deployment and sets status message if there are the target three replicas ready:
public class ExpectationReconciler implements Reconciler<ExpectationCustomResource> {
// some code is omitted
private final ExpectationManager<ExpectationCustomResource> expectationManager =
new ExpectationManager<>();
@Override
public UpdateControl<ExpectationCustomResource> reconcile(
ExpectationCustomResource primary, Context<ExpectationCustomResource> context) {
// exiting asap if there is an expectation that is not timed out neither fulfilled yet
if (expectationManager.ongoingExpectationPresent(primary, context)) {
return UpdateControl.noUpdate();
}
var deployment = context.getSecondaryResource(Deployment.class);
if (deployment.isEmpty()) {
createDeployment(primary, context);
expectationManager.setExpectation(
primary, Duration.ofSeconds(timeout), deploymentReadyExpectation());
return UpdateControl.noUpdate();
} else {
// Checks the expectation and removes it once it is fulfilled.
// In your logic you might add a next expectation based on your workflow.
// Expectations have a name, so you can easily distinguish multiple expectations.
var res = expectationManager.checkExpectation("deploymentReadyExpectation", primary, context);
if (res.isFulfilled()) {
return pathchStatusWithMessage(primary, DEPLOYMENT_READY);
} else if (res.isTimedOut()) {
// you might add some other timeout handling here
return pathchStatusWithMessage(primary, DEPLOYMENT_TIMEOUT);
}
}
return UpdateControl.noUpdate();
}
}
2.2 - Error handling and retries
How Automatic Retries Work
JOSDK automatically schedules retries whenever your Reconciler throws an exception. This robust retry mechanism helps handle transient issues like network problems or temporary resource unavailability.
Default Retry Behavior
The default retry implementation covers most typical use cases with exponential backoff:
GenericRetry.defaultLimitedExponentialRetry()
.setInitialInterval(5000) // Start with 5-second delay
.setIntervalMultiplier(1.5D) // Increase delay by 1.5x each retry
.setMaxAttempts(5); // Maximum 5 attempts
Configuration Options
Using the @GradualRetry annotation:
@ControllerConfiguration
@GradualRetry(maxAttempts = 3, initialInterval = 2000)
public class MyReconciler implements Reconciler<MyResource> {
// reconciler implementation
}
Custom retry implementation:
Specify a custom retry class in the @ControllerConfiguration annotation:
@ControllerConfiguration(retry = MyCustomRetry.class)
public class MyReconciler implements Reconciler<MyResource> {
// reconciler implementation
}
Your custom retry class must:
- Provide a no-argument constructor for automatic instantiation
- Optionally implement
AnnotationConfigurablefor configuration from annotations. SeeGenericRetryimplementation for more details.
Accessing Retry Information
The Context object provides retry state information:
@Override
public UpdateControl<MyResource> reconcile(MyResource resource, Context<MyResource> context) {
if (context.isLastAttempt()) {
// Handle final retry attempt differently
resource.getStatus().setErrorMessage("Failed after all retry attempts");
return UpdateControl.patchStatus(resource);
}
// Normal reconciliation logic
// ...
}
Important Retry Behavior Notes
- Retry limits don’t block new events: When retry limits are reached, new reconciliations still occur for new events
- No retry on limit reached: If an error occurs after reaching the retry limit, no additional retries are scheduled until new events arrive
- Event-driven recovery: Fresh events can restart the retry cycle, allowing recovery from previously failed states
A successful execution resets the retry state.
Reconciler Error Handler
In order to facilitate error reporting you can override updateErrorStatus
method in Reconciler:
public class MyReconciler implements Reconciler<WebPage> {
@Override
public ErrorStatusUpdateControl<WebPage> updateErrorStatus(
WebPage resource, Context<WebPage> context, Exception e) {
return handleError(resource, e);
}
}
The updateErrorStatus method is called in case an exception is thrown from the Reconciler. It is
also called even if no retry policy is configured, just after the reconciler execution.
RetryInfo.getAttemptCount() is zero after the first reconciliation attempt, since it is not a
result of a retry (regardless of whether a retry policy is configured).
ErrorStatusUpdateControl tells the SDK what to do and how to perform the status
update on the primary resource, which is always performed as a status sub-resource request. Note that
this update request will also produce an event and result in a reconciliation if the
controller is not generation-aware.
This feature is only available for the reconcile method of the Reconciler interface, since
there should not be updates to resources that have been marked for deletion.
Retry can be skipped in cases of unrecoverable errors:
ErrorStatusUpdateControl.patchStatus(customResource).withNoRetry();
Correctness and Automatic Retries
While it is possible to deactivate automatic retries, this is not desirable unless there is a particular reason.
Errors naturally occur, whether it be transient network errors or conflicts
when a given resource is handled by a Reconciler but modified simultaneously by a user in
a different process. Automatic retries handle these cases nicely and will eventually result in a
successful reconciliation.
Retry, Rescheduling and Event Handling Common Behavior
Retry, reschedule, and standard event processing form a relatively complex system, each of these functionalities interacting with the others. In the following, we describe the interplay of these features:
A successful execution resets a retry and the rescheduled executions that were present before the reconciliation. However, the reconciliation outcome can instruct a new rescheduling (
UpdateControlorDeleteControl).For example, if a reconciliation had previously been rescheduled for after some amount of time, but an event triggered the reconciliation (or cleanup) in the meantime, the scheduled execution would be automatically cancelled, i.e. rescheduling a reconciliation does not guarantee that one will occur precisely at that time; it simply guarantees that a reconciliation will occur at the latest. Of course, it’s always possible to reschedule a new reconciliation at the end of that “automatic” reconciliation.
Similarly, if a retry was scheduled, any event from the cluster triggering a successful execution in the meantime would cancel the scheduled retry (because there’s now no point in retrying something that already succeeded)
In case an exception is thrown, a retry is initiated. However, if an event is received meanwhile, it will be reconciled instantly, and this execution won’t count as a retry attempt.
If the retry limit is reached (so no more automatic retry would happen), but a new event received, the reconciliation will still happen, but won’t reset the retry, and will still be marked as the last attempt in the retry info. The point (1) still holds - thus successful reconciliation will reset the retry - but no retry will happen in case of an error.
The thing to remember when it comes to retrying or rescheduling is that JOSDK tries to avoid unnecessary work. When you reschedule an operation, you instruct JOSDK to perform that operation by the end of the rescheduling delay at the latest. If something occurred on the cluster that triggers that particular operation (reconciliation or cleanup), then JOSDK considers that there’s no point in attempting that operation again at the end of the specified delay since there is no point in doing so anymore. The same idea also applies to retries.
2.3 - Event sources and related topics
Handling Related Events with Event Sources
See also this blog post .
Event sources are a relatively simple yet powerful and extensible concept to trigger controller
executions, usually based on changes to dependent resources. You typically need an event source
when you want your Reconciler to be triggered when something occurs to secondary resources
that might affect the state of your primary resource. This is needed because a given
Reconciler will only listen by default to events affecting the primary resource type it is
configured for. Event sources act as listen to events affecting these secondary resources so
that a reconciliation of the associated primary resource can be triggered when needed. Note that
these secondary resources need not be Kubernetes resources. Typically, when dealing with
non-Kubernetes objects or services, we can extend our operator to handle webhooks or websockets
or to react to any event coming from a service we interact with. This allows for very efficient
controller implementations because reconciliations are then only triggered when something occurs
on resources affecting our primary resources thus doing away with the need to periodically
reschedule reconciliations.
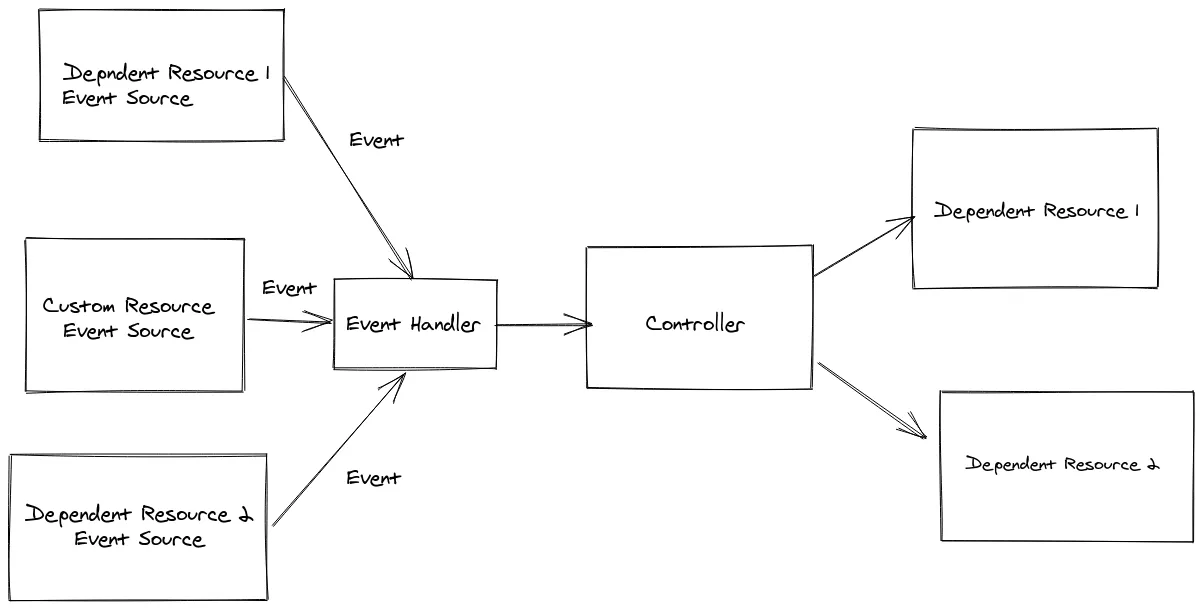
There are few interesting points here:
The CustomResourceEventSource event source is a special one, responsible for handling events
pertaining to changes affecting our primary resources. This EventSource is always registered
for every controller automatically by the SDK. It is important to note that events always relate
to a given primary resource. Concurrency is still handled for you, even in the presence of
EventSource implementations, and the SDK still guarantees that there is no concurrent execution of
the controller for any given primary resource (though, of course, concurrent/parallel executions
of events pertaining to other primary resources still occur as expected).
Caching and Event Sources
Kubernetes resources are handled in a declarative manner. The same also holds true for event
sources. For example, if we define an event source to watch for changes of a Kubernetes Deployment
object using an InformerEventSource, we always receive the whole associated object from the
Kubernetes API. This object might be needed at any point during our reconciliation process and
it’s best to retrieve it from the event source directly when possible instead of fetching it
from the Kubernetes API since the event source guarantees that it will provide the latest
version. Not only that, but many event source implementations also cache resources they handle
so that it’s possible to retrieve the latest version of resources without needing to make any
calls to the Kubernetes API, thus allowing for very efficient controller implementations.
Note after an operator starts, caches are already populated by the time the first reconciliation
is processed for the InformerEventSource implementation. However, this does not necessarily
hold true for all event source implementations (PerResourceEventSource for example). The SDK
provides methods to handle this situation elegantly, allowing you to check if an object is
cached, retrieving it from a provided supplier if not. See
related method
.
Registering Event Sources
To register event sources, your Reconciler has to override the prepareEventSources and return
list of event sources to register. One way to see this in action is
to look at the
WebPage example
(irrelevant details omitted):
import java.util.List;
@ControllerConfiguration
public class WebappReconciler
implements Reconciler<Webapp>, Cleaner<Webapp>, EventSourceInitializer<Webapp> {
// ommitted code
@Override
public List<EventSource<?, Webapp>> prepareEventSources(EventSourceContext<Webapp> context) {
InformerEventSourceConfiguration<Webapp> configuration =
InformerEventSourceConfiguration.from(Deployment.class, Webapp.class)
.withLabelSelector(SELECTOR)
.build();
return List.of(new InformerEventSource<>(configuration, context));
}
}
In the example above an InformerEventSource is configured and registered.
InformerEventSource is one of the bundled EventSource implementations that JOSDK provides to
cover common use cases.
Managing Relation between Primary and Secondary Resources
Event sources let your operator know when a secondary resource has changed and that your
operator might need to reconcile this new information. However, in order to do so, the SDK needs
to somehow retrieve the primary resource associated with which ever secondary resource triggered
the event. In the Webapp example above, when an event occurs on a tracked Deployment, the
SDK needs to be able to identify which Webapp resource is impacted by that change.
Seasoned Kubernetes users already know one way to track this parent-child kind of relationship: using owner references. Indeed, that’s how the SDK deals with this situation by default as well, that is, if your controller properly set owner references on your secondary resources, the SDK will be able to follow that reference back to your primary resource automatically without you having to worry about it.
However, owner references cannot always be used as they are restricted to operating within a single namespace (i.e. you cannot have an owner reference to a resource in a different namespace) and are, by essence, limited to Kubernetes resources so you’re out of luck if your secondary resources live outside of a cluster.
This is why JOSDK provides the SecondaryToPrimaryMapper interface so that you can provide
alternative ways for the SDK to identify which primary resource needs to be reconciled when
something occurs to your secondary resources. We even provide some of these alternatives in the
Mappers
class.
Note that, while a set of ResourceID is returned, this set usually consists only of one
element. It is however possible to return multiple values or even no value at all to cover some
rare corner cases. Returning an empty set means that the mapper considered the secondary
resource event as irrelevant and the SDK will thus not trigger a reconciliation of the primary
resource in that situation.
Adding a SecondaryToPrimaryMapper is typically sufficient when there is a one-to-many relationship
between primary and secondary resources. The secondary resources can be mapped to its primary
owner, and this is enough information to also get these secondary resources from the Context
object that’s passed to your Reconciler.
There are however cases when this isn’t sufficient and you need to provide an explicit mapping
between a primary resource and its associated secondary resources using an implementation of the
PrimaryToSecondaryMapper interface. This is typically needed when there are many-to-one or
many-to-many relationships between primary and secondary resources, e.g. when the primary resource
is referencing secondary resources.
See PrimaryToSecondaryIT
integration test for a sample.
Built-in EventSources
There are multiple event-sources provided out of the box, the following are some more central ones:
InformerEventSource
InformerEventSource
is probably the most important EventSource implementation to know about. When you create an
InformerEventSource, JOSDK will automatically create and register a SharedIndexInformer, a
fabric8 Kubernetes client class, that will listen for events associated with the resource type
you configured your InformerEventSource with. If you want to listen to Kubernetes resource
events, InformerEventSource is probably the only thing you need to use. It’s highly
configurable so you can tune it to your needs. Take a look at
InformerEventSourceConfiguration
and associated classes for more details but some interesting features we can mention here is the
ability to filter events so that you can only get notified for events you care about. A
particularly interesting feature of the InformerEventSource, as opposed to using your own
informer-based listening mechanism is that caches are particularly well optimized preventing
reconciliations from being triggered when not needed and allowing efficient operators to be written.
PerResourcePollingEventSource
PerResourcePollingEventSource is used to poll external APIs, which don’t support webhooks or other event notifications. It extends the abstract ExternalResourceCachingEventSource to support caching. See MySQL Schema sample for usage.
PollingEventSource
PollingEventSource
is similar to PerResourceCachingEventSource except that, contrary to that event source, it
doesn’t poll a specific API separately per resource, but periodically and independently of
actually observed primary resources.
Inbound event sources
SimpleInboundEventSource and CachingInboundEventSource are used to handle incoming events from webhooks and messaging systems.
ControllerResourceEventSource
ControllerResourceEventSource
is a special EventSource implementation that you will never have to deal with directly. It is,
however, at the core of the SDK is automatically added for you: this is the main event source
that listens for changes to your primary resources and triggers your Reconciler when needed.
It features smart caching and is really optimized to minimize Kubernetes API accesses and avoid
triggering unduly your Reconciler.
More on the philosophy of the non Kubernetes API related event source see in issue #729.
InformerEventSource Multi-Cluster Support
It is possible to handle resources for remote cluster with InformerEventSource. To do so,
simply set a client that connects to a remote cluster:
InformerEventSourceConfiguration<WebPage> configuration =
InformerEventSourceConfiguration.from(SecondaryResource.class, PrimaryResource.class)
.withKubernetesClient(remoteClusterClient)
.withSecondaryToPrimaryMapper(Mappers.fromDefaultAnnotations());
You will also need to specify a SecondaryToPrimaryMapper, since the default one
is based on owner references and won’t work across cluster instances. You could, for example, use the provided implementation that relies on annotations added to the secondary resources to identify the associated primary resource.
See related integration test.
Generation Awareness and Event Filtering
A best practice when an operator starts up is to reconcile all the associated resources because changes might have occurred to the resources while the operator was not running.
When this first reconciliation is done successfully, the next reconciliation is triggered if either
dependent resources are changed or the primary resource .spec field is changed. If other fields
like .metadata are changed on the primary resource, the reconciliation could be skipped. This
behavior is supported out of the box and reconciliation is by default not triggered if
changes to the primary resource do not increase the .metadata.generation field.
Note that changes to .metada.generation are automatically handled by Kubernetes.
To turn off this feature, set generationAwareEventProcessing to false for the Reconciler.
Max Interval Between Reconciliations
When informers / event sources are properly set up, and the Reconciler implementation is
correct, no additional reconciliation triggers should be needed. However, it’s
a common practice
to have a failsafe periodic trigger in place, just to make sure resources are nevertheless
reconciled after a certain amount of time. This functionality is in place by default, with a
rather high time interval (currently 10 hours) after which a reconciliation will be
automatically triggered even in the absence of other events. See how to override this using the
standard annotation:
@ControllerConfiguration(maxReconciliationInterval = @MaxReconciliationInterval(
interval = 50,
timeUnit = TimeUnit.MILLISECONDS))
public class MyReconciler implements Reconciler<HasMetadata> {}
The event is not propagated at a fixed rate, rather it’s scheduled after each reconciliation. So the next reconciliation will occur at most within the specified interval after the last reconciliation.
This feature can be turned off by setting maxReconciliationInterval
to Constants.NO_MAX_RECONCILIATION_INTERVAL
or any non-positive number.
The automatic retries are not affected by this feature so a reconciliation will be re-triggered on error, according to the specified retry policy, regardless of this maximum interval setting.
Rate Limiting
It is possible to rate limit reconciliation on a per-resource basis. The rate limit also takes precedence over retry/re-schedule configurations: for example, even if a retry was scheduled for the next second but this request would make the resource go over its rate limit, the next reconciliation will be postponed according to the rate limiting rules. Note that the reconciliation is never cancelled, it will just be executed as early as possible based on rate limitations.
Rate limiting is by default turned off, since correct configuration depends on the reconciler
implementation, in particular, on how long a typical reconciliation takes.
(The parallelism of reconciliation itself can be
limited ConfigurationService
by configuring the ExecutorService appropriately.)
A default rate limiter implementation is provided, see:
PeriodRateLimiter
.
Users can override it by implementing their own
RateLimiter
and specifying this custom implementation using the rateLimiter field of the
@ControllerConfiguration annotation. Similarly to the Retry implementations,
RateLimiter implementations must provide an accessible, no-arg constructor for instantiation
purposes and can further be automatically configured from your own, provided annotation provided
your RateLimiter implementation also implements the AnnotationConfigurable interface,
parameterized by your custom annotation type.
To configure the default rate limiter use the @RateLimited annotation on your
Reconciler class. The following configuration limits each resource to reconcile at most twice
within a 3 second interval:
@RateLimited(maxReconciliations = 2, within = 3, unit = TimeUnit.SECONDS)
@ControllerConfiguration
public class MyReconciler implements Reconciler<MyCR> {
}
Thus, if a given resource was reconciled twice in one second, no further reconciliation for this resource will happen before two seconds have elapsed. Note that, since rate is limited on a per-resource basis, other resources can still be reconciled at the same time, as long, of course, that they stay within their own rate limits.
Optimizing Caches
One of the ideas around the operator pattern is that all the relevant resources are cached, thus reconciliation is usually very fast (especially if no resources are updated in the process) since the operator is then mostly working with in-memory state. However for large clusters, caching huge amount of primary and secondary resources might consume lots of memory. JOSDK provides ways to mitigate this issue and optimize the memory usage of controllers. While these features are working and tested, we need feedback from real production usage.
Bounded Caches for Informers
Limiting caches for informers - thus for Kubernetes resources - is supported by ensuring that resources are in the cache for a limited time, via a cache eviction of least recently used resources. This means that when resources are created and frequently reconciled, they stay “hot” in the cache. However, if, over time, a given resource “cools” down, i.e. it becomes less and less used to the point that it might not be reconciled anymore, it will eventually get evicted from the cache to free up memory. If such an evicted resource were to become reconciled again, the bounded cache implementation would then fetch it from the API server and the “hot/cold” cycle would start anew.
Since all resources need to be reconciled when a controller start, it is not practical to set a maximal cache size as it’s desirable that all resources be cached as soon as possible to make the initial reconciliation process on start as fast and efficient as possible, avoiding undue load on the API server. It’s therefore more interesting to gradually evict cold resources than try to limit cache sizes.
See usage of the related implementation using Caffeine cache in integration tests for primary resources.
See also CaffeineBoundedItemStores for more details.
2.4 - Working with EventSource caches
As described in Event sources and related topics, event sources serve as the backbone for caching resources and triggering reconciliation for primary resources that are related to these secondary resources.
In the Kubernetes ecosystem, the component responsible for this is called an Informer. Without delving into the details (there are plenty of excellent resources online about informers), informers watch resources, cache them, and emit events when resources change.
EventSource is a generalized concept that extends the Informer pattern to non-Kubernetes resources,
allowing you to cache external resources and trigger reconciliation when those resources change.
The InformerEventSource
The underlying informer implementation comes from the Fabric8 client, called DefaultSharedIndexInformer. InformerEventSource in Java Operator SDK wraps the Fabric8 client informers. While this wrapper adds additional capabilities specifically required for controllers, this is the event source that most likely will be used to deal with Kubernetes resources.
These additional capabilities include:
- Maintaining an index that maps secondary resources in the informer cache to their related primary resources
- Setting up multiple informers for the same resource type when needed (for example, you need one informer per namespace if the informer is not watching the entire cluster)
- Dynamically adding and removing watched namespaces
- Other capabilities that are beyond the scope of this document
Associating Secondary Resources to Primary Resource
Event sources need to trigger the appropriate reconciler, providing the correct primary resource, whenever one of their
handled secondary resources changes. It is thus core to an event source’s role to identify which primary resource
(usually, your custom resource) is potentially impacted by that change.
The framework uses SecondaryToPrimaryMapper
for this purpose. For InformerEventSources, which target Kubernetes resources, this mapping is typically done using
either the owner reference or an annotation on the secondary resource. For external resources, other mechanisms need to
be used and there are also cases where the default mechanisms provided by the SDK do not work, even for Kubernetes
resources.
However, once the event source has triggered a primary resource reconciliation, the associated reconciler needs to
access the secondary resources which changes caused the reconciliation. Indeed, the information from the secondary
resources might be needed during the reconciliation. For that purpose,InformerEventSource maintains a reverse
index PrimaryToSecondaryIndex,
based on the result of the SecondaryToPrimaryMapperresult.
Unified API for Related Resources
To access all related resources for a primary resource, the framework provides an API to access the related
secondary resources using the Set<R> getSecondaryResources(Class<R> expectedType) method of the Context object
provided as part of the reconcile method.
For InformerEventSource, this will leverage the associated PrimaryToSecondaryIndex. Resources are then retrieved
from the informer’s cache. Note that since all those steps work on top of indexes, those operations are very fast,
usually O(1).
While we’ve focused mostly on InformerEventSource, this concept can be extended to all EventSources, since
EventSource
actually implements the Set<R> getSecondaryResources(P primary) method that can be called from the Context.
As there can be multiple event sources for the same resource types, things are a little more complex: the union of each event source results is returned.
Getting Resources Directly from Event Sources
Note that nothing prevents you from directly accessing resources in the cache without going through
getSecondaryResources(...):
public class WebPageReconciler implements Reconciler<WebPage> {
InformerEventSource<ConfigMap, WebPage> configMapEventSource;
@Override
public UpdateControl<WebPage> reconcile(WebPage webPage, Context<WebPage> context) {
// accessing resource directly from an event source
var mySecondaryResource = configMapEventSource.get(new ResourceID("name","namespace"));
// details omitted
}
@Override
public List<EventSource<?, WebPage>> prepareEventSources(EventSourceContext<WebPage> context) {
configMapEventSource = new InformerEventSource<>(
InformerEventSourceConfiguration.from(ConfigMap.class, WebPage.class)
.withLabelSelector(SELECTOR)
.build(),
context);
return List.of(configMapEventSource);
}
}
The Use Case for PrimaryToSecondaryMapper
TL;DR: PrimaryToSecondaryMapper allows InformerEventSource to access secondary resources directly
instead of using the PrimaryToSecondaryIndex. When this mapper is configured, InformerEventSource.getSecondaryResources(..)
will call the mapper to retrieve the target secondary resources. This is typically required when the SecondaryToPrimaryMapper
uses informer caches to list the target resources.
As discussed, we provide a unified API to access related resources using Context.getSecondaryResources(...).
The term “Secondary” refers to resources that a reconciler needs to consider when properly reconciling a primary
resource. These resources encompass more than just “child” resources (resources created by a reconciler that
typically have an owner reference pointing to the primary custom resource). They also include
“related” resources (which may or may not be managed by Kubernetes) that serve as input for reconciliations.
In some cases, the SDK needs additional information beyond what’s readily available, particularly when secondary resources lack owner references or any direct link to their associated primary resource.
Consider this example: a Job primary resource can be assigned to run on a cluster, represented by a
Cluster resource.
Multiple jobs can run on the same cluster, so multiple Job resources can reference the same Cluster resource. However,
a Cluster resource shouldn’t know about Job resources, as this information isn’t part of what defines a cluster.
When a cluster changes, though, we might want to redirect associated jobs to other clusters. Our reconciler
therefore needs to determine which Job (primary) resources are associated with the changed Cluster (secondary)
resource.
See full
sample here.
InformerEventSourceConfiguration
.from(Cluster.class, Job.class)
.withSecondaryToPrimaryMapper(cluster ->
context.getPrimaryCache()
.list()
.filter(job -> job.getSpec().getClusterName().equals(cluster.getMetadata().getName()))
.map(ResourceID::fromResource)
.collect(Collectors.toSet()))
This configuration will trigger all related Jobs when the associated cluster changes and maintains the PrimaryToSecondaryIndex,
allowing us to use getSecondaryResources in the Job reconciler to access the cluster.
However, there’s a potential issue: when a new Job is created, it doesn’t automatically propagate
to the PrimaryToSecondaryIndex in the Cluster’s InformerEventSource. Re-indexing only occurs
when a Cluster event is received, which triggers all related Jobs again.
Until this re-indexing happens, you cannot use getSecondaryResources for the new Job, since it
won’t be present in the reverse index.
You can work around this by accessing the Cluster directly from the cache in the reconciler:
@Override
public UpdateControl<Job> reconcile(Job resource, Context<Job> context) {
clusterInformer.get(new ResourceID(job.getSpec().getClusterName(), job.getMetadata().getNamespace()));
// omitted details
}
However, if you prefer to use the unified API (context.getSecondaryResources()), you need to add
a PrimaryToSecondaryMapper:
clusterInformer.withPrimaryToSecondaryMapper( job ->
Set.of(new ResourceID(job.getSpec().getClusterName(), job.getMetadata().getNamespace())));
When using PrimaryToSecondaryMapper, the InformerEventSource bypasses the PrimaryToSecondaryIndex
and instead calls the mapper to retrieve resources based on its results.
In fact, when this mapper is configured, the PrimaryToSecondaryIndex isn’t even initialized.
Using Informer Indexes to Improve Performance
In the SecondaryToPrimaryMapper example above, we iterate through all resources in the cache:
context.getPrimaryCache().list().filter(job -> job.getSpec().getClusterName().equals(cluster.getMetadata().getName()))
This approach can be inefficient when dealing with a large number of primary (Job) resources. To improve performance,
you can create an index in the underlying Informer that indexes the target jobs for each cluster:
@Override
public List<EventSource<?, Job>> prepareEventSources(EventSourceContext<Job> context) {
context.getPrimaryCache()
.addIndexer(JOB_CLUSTER_INDEX,
(job -> List.of(indexKey(job.getSpec().getClusterName(), job.getMetadata().getNamespace()))));
// omitted details
}
where indexKey is a String that uniquely identifies a Cluster:
private String indexKey(String clusterName, String namespace) {
return clusterName + "#" + namespace;
}
With this index in place, you can retrieve the target resources very efficiently:
InformerEventSource<Job,Cluster> clusterInformer =
new InformerEventSource(
InformerEventSourceConfiguration.from(Cluster.class, Job.class)
.withSecondaryToPrimaryMapper(
cluster ->
context
.getPrimaryCache()
.byIndex(
JOB_CLUSTER_INDEX,
indexKey(
cluster.getMetadata().getName(),
cluster.getMetadata().getNamespace()))
.stream()
.map(ResourceID::fromResource)
.collect(Collectors.toSet()))
.withNamespacesInheritedFromController().build(), context);
2.5 - Configurations
The Java Operator SDK (JOSDK) provides abstractions that work great out of the box. However, we recognize that default behavior isn’t always suitable for every use case. Numerous configuration options help you tailor the framework to your specific needs.
Configuration options operate at several levels:
- Operator-level using
ConfigurationService - Reconciler-level using
ControllerConfiguration - DependentResource-level using the
DependentResourceConfiguratorinterface - EventSource-level where some event sources (like
InformerEventSource) need fine-tuning to identify which events trigger the associated reconciler
Operator-Level Configuration
Configuration that impacts the entire operator is performed via the ConfigurationService class. ConfigurationService is an abstract class with different implementations based on which framework flavor you use (e.g., Quarkus Operator SDK replaces the default implementation). Configurations initialize with sensible defaults but can be changed during initialization.
For example, to disable CRD validation on startup and configure leader election:
Operator operator = new Operator( override -> override
.checkingCRDAndValidateLocalModel(false)
.withLeaderElectionConfiguration(new LeaderElectionConfiguration("bar", "barNS")));
Reconciler-Level Configuration
While reconcilers are typically configured using the @ControllerConfiguration annotation, you can also override configuration at runtime when registering the reconciler with the operator. You can either:
- Pass a completely new
ControllerConfigurationinstance - Override specific aspects using a
ControllerConfigurationOverriderConsumer(preferred)
Operator operator;
Reconciler reconciler;
...
operator.register(reconciler, configOverrider ->
configOverrider.withFinalizer("my-nifty-operator/finalizer").withLabelSelector("foo=bar"));
Dynamically Changing Target Namespaces
A controller can be configured to watch a specific set of namespaces in addition of the
namespace in which it is currently deployed or the whole cluster. The framework supports
dynamically changing the list of these namespaces while the operator is running.
When a reconciler is registered, an instance of
RegisteredController
is returned, providing access to the methods allowing users to change watched namespaces as the
operator is running.
A typical scenario would probably involve extracting the list of target namespaces from a
ConfigMap or some other input but this part is out of the scope of the framework since this is
use-case specific. For example, reacting to changes to a ConfigMap would probably involve
registering an associated Informer and then calling the changeNamespaces method on
RegisteredController.
public static void main(String[] args) {
KubernetesClient client = new DefaultKubernetesClient();
Operator operator = new Operator(client);
RegisteredController registeredController = operator.register(new WebPageReconciler(client));
operator.installShutdownHook();
operator.start();
// call registeredController further while operator is running
}
If watched namespaces change for a controller, it might be desirable to propagate these changes to
InformerEventSources associated with the controller. In order to express this,
InformerEventSource implementations interested in following such changes need to be
configured appropriately so that the followControllerNamespaceChanges method returns true:
@ControllerConfiguration
public class MyReconciler implements Reconciler<TestCustomResource> {
@Override
public Map<String, EventSource> prepareEventSources(
EventSourceContext<ChangeNamespaceTestCustomResource> context) {
InformerEventSource<ConfigMap, TestCustomResource> configMapES =
new InformerEventSource<>(InformerEventSourceConfiguration.from(ConfigMap.class, TestCustomResource.class)
.withNamespacesInheritedFromController(context)
.build(), context);
return EventSourceUtils.nameEventSources(configMapES);
}
}
As seen in the above code snippet, the informer will have the initial namespaces inherited from controller, but also will adjust the target namespaces if it changes for the controller.
See also the integration test for this feature.
DependentResource-level configuration
It is possible to define custom annotations to configure custom DependentResource implementations. In order to provide
such a configuration mechanism for your own DependentResource implementations, they must be annotated with the
@Configured annotation. This annotation defines 3 fields that tie everything together:
by, which specifies which annotation class will be used to configure your dependents,with, which specifies the class holding the configuration object for your dependents andconverter, which specifies theConfigurationConverterimplementation in charge of converting the annotation specified by thebyfield into objects of the class specified by thewithfield.
ConfigurationConverter instances implement a single configFrom method, which will receive, as expected, the
annotation instance annotating the dependent resource instance to be configured, but it can also extract information
from the DependentResourceSpec instance associated with the DependentResource class so that metadata from it can be
used in the configuration, as well as the parent ControllerConfiguration, if needed. The role of
ConfigurationConverter implementations is to extract the annotation information, augment it with metadata from the
DependentResourceSpec and the configuration from the parent controller on which the dependent is defined, to finally
create the configuration object that the DependentResource instances will use.
However, one last element is required to finish the configuration process: the target DependentResource class must
implement the ConfiguredDependentResource interface, parameterized with the annotation class defined by the
@Configured annotation by field. This interface is called by the framework to inject the configuration at the
appropriate time and retrieve the configuration, if it’s available.
For example, KubernetesDependentResource, a core implementation that the framework provides, can be configured via the
@KubernetesDependent annotation. This set up is configured as follows:
@Configured(
by = KubernetesDependent.class,
with = KubernetesDependentResourceConfig.class,
converter = KubernetesDependentConverter.class)
public abstract class KubernetesDependentResource<R extends HasMetadata, P extends HasMetadata>
extends AbstractEventSourceHolderDependentResource<R, P, InformerEventSource<R, P>>
implements ConfiguredDependentResource<KubernetesDependentResourceConfig<R>> {
// code omitted
}
The @Configured annotation specifies that KubernetesDependentResource instances can be configured by using the
@KubernetesDependent annotation, which gets converted into a KubernetesDependentResourceConfig object by a
KubernetesDependentConverter. That configuration object is then injected by the framework in the
KubernetesDependentResource instance, after it’s been created, because the class implements the
ConfiguredDependentResource interface, properly parameterized.
For more information on how to use this feature, we recommend looking at how this mechanism is implemented for
KubernetesDependentResource in the core framework, SchemaDependentResource in the samples or CustomAnnotationDep
in the BaseConfigurationServiceTest test class.
EventSource-level configuration
TODO
2.6 - Observability
Runtime Info
RuntimeInfo is used mainly to check the actual health of event sources. Based on this information it is easy to implement custom liveness probes.
stopOnInformerErrorDuringStartup setting, where this flag usually needs to be set to false, in order to control the exact liveness properties.
See also an example implementation in the WebPage sample
Contextual Info for Logging with MDC
Logging is enhanced with additional contextual information using MDC. The following attributes are available in most parts of reconciliation logic and during the execution of the controller:
| MDC Key | Value added from primary resource |
|---|---|
resource.apiVersion | .apiVersion |
resource.kind | .kind |
resource.name | .metadata.name |
resource.namespace | .metadata.namespace |
resource.resourceVersion | .metadata.resourceVersion |
resource.generation | .metadata.generation |
resource.uid | .metadata.uid |
For more information about MDC see this link.
Metrics
JOSDK provides built-in support for metrics reporting on what is happening with your reconcilers in the form of
the Metrics interface which can be implemented to connect to your metrics provider of choice, JOSDK calling the
methods as it goes about reconciling resources. By default, a no-operation implementation is provided thus providing a
no-cost sane default. A micrometer-based implementation is also provided.
You can use a different implementation by overriding the default one provided by the default ConfigurationService, as
follows:
Metrics metrics; // initialize your metrics implementation
Operator operator = new Operator(client, o -> o.withMetrics(metrics));
Micrometer implementation
The micrometer implementation is typically created using one of the provided factory methods which, depending on which is used, will return either a ready to use instance or a builder allowing users to customize how the implementation behaves, in particular when it comes to the granularity of collected metrics. It is, for example, possible to collect metrics on a per-resource basis via tags that are associated with meters. This is the default, historical behavior but this will change in a future version of JOSDK because this dramatically increases the cardinality of metrics, which could lead to performance issues.
To create a MicrometerMetrics implementation that behaves how it has historically behaved, you can just create an
instance via:
MeterRegistry registry; // initialize your registry implementation
Metrics metrics = MicrometerMetrics.newMicrometerMetricsBuilder(registry).build();
The class provides factory methods which either return a fully pre-configured instance or a builder object that will allow you to configure more easily how the instance will behave. You can, for example, configure whether the implementation should collect metrics on a per-resource basis, whether associated meters should be removed when a resource is deleted and how the clean-up is performed. See the relevant classes documentation for more details.
For example, the following will create a MicrometerMetrics instance configured to collect metrics on a per-resource
basis, deleting the associated meters after 5 seconds when a resource is deleted, using up to 2 threads to do so.
MicrometerMetrics.newPerResourceCollectingMicrometerMetricsBuilder(registry)
.withCleanUpDelayInSeconds(5)
.withCleaningThreadNumber(2)
.build();
Operator SDK metrics
The micrometer implementation records the following metrics:
| Meter name | Type | Tag names | Description |
|---|---|---|---|
operator.sdk.reconciliations.executions.<reconciler name> | gauge | group, version, kind | Number of executions of the named reconciler |
operator.sdk.reconciliations.queue.size.<reconciler name> | gauge | group, version, kind | How many resources are queued to get reconciled by named reconciler |
operator.sdk.<map name>.size | gauge map size | Gauge tracking the size of a specified map (currently unused but could be used to monitor caches size) | |
| operator.sdk.events.received | counter | <resource metadata>, event, action | Number of received Kubernetes events |
| operator.sdk.events.delete | counter | <resource metadata> | Number of received Kubernetes delete events |
| operator.sdk.reconciliations.started | counter | <resource metadata>, reconciliations.retries.last, reconciliations.retries.number | Number of started reconciliations per resource type |
| operator.sdk.reconciliations.failed | counter | <resource metadata>, exception | Number of failed reconciliations per resource type |
| operator.sdk.reconciliations.success | counter | <resource metadata> | Number of successful reconciliations per resource type |
| operator.sdk.controllers.execution.reconcile | timer | <resource metadata>, controller | Time taken for reconciliations per controller |
| operator.sdk.controllers.execution.cleanup | timer | <resource metadata>, controller | Time taken for cleanups per controller |
| operator.sdk.controllers.execution.reconcile.success | counter | controller, type | Number of successful reconciliations per controller |
| operator.sdk.controllers.execution.reconcile.failure | counter | controller, exception | Number of failed reconciliations per controller |
| operator.sdk.controllers.execution.cleanup.success | counter | controller, type | Number of successful cleanups per controller |
| operator.sdk.controllers.execution.cleanup.failure | counter | controller, exception | Number of failed cleanups per controller |
As you can see all the recorded metrics start with the operator.sdk prefix. <resource metadata>, in the table above,
refers to resource-specific metadata and depends on the considered metric and how the implementation is configured and
could be summed up as follows: group?, version, kind, [name, namespace?], scope where the tags in square
brackets ([]) won’t be present when per-resource collection is disabled and tags followed by a question mark are
omitted if the associated value is empty. Of note, when in the context of controllers’ execution metrics, these tag
names are prefixed with resource.. This prefix might be removed in a future version for greater consistency.
Aggregated Metrics
The AggregatedMetrics class provides a way to combine multiple metrics providers into a single metrics instance using
the composite pattern. This is particularly useful when you want to simultaneously collect metrics data from different
monitoring systems or providers.
You can create an AggregatedMetrics instance by providing a list of existing metrics implementations:
// create individual metrics instances
Metrics micrometerMetrics = MicrometerMetrics.withoutPerResourceMetrics(registry);
Metrics customMetrics = new MyCustomMetrics();
Metrics loggingMetrics = new LoggingMetrics();
// combine them into a single aggregated instance
Metrics aggregatedMetrics = new AggregatedMetrics(List.of(
micrometerMetrics,
customMetrics,
loggingMetrics
));
// use the aggregated metrics with your operator
Operator operator = new Operator(client, o -> o.withMetrics(aggregatedMetrics));
This approach allows you to easily combine different metrics collection strategies, such as sending metrics to both Prometheus (via Micrometer) and a custom logging system simultaneously.
2.7 - Other Features
The Java Operator SDK (JOSDK) is a high-level framework and tooling suite for implementing Kubernetes operators. By default, features follow best practices in an opinionated way. However, configuration options and feature flags are available to fine-tune or disable these features.
Support for Well-Known Kubernetes Resources
Controllers can be registered for standard Kubernetes resources (not just custom resources), such as Ingress, Deployment, and others.
See the integration test for an example of reconciling deployments.
public class DeploymentReconciler
implements Reconciler<Deployment>, TestExecutionInfoProvider {
@Override
public UpdateControl<Deployment> reconcile(
Deployment resource, Context context) {
// omitted code
}
}
Leader Election
Operators are typically deployed with a single active instance. However, you can deploy multiple instances where only one (the “leader”) processes events. This is achieved through “leader election.”
While all instances run and start their event sources to populate caches, only the leader processes events. If the leader crashes, other instances are already warmed up and ready to take over when a new leader is elected.
See sample configuration in the E2E test.
Automatic CRD Generation
Note: This feature is provided by the Fabric8 Kubernetes Client, not JOSDK itself.
To automatically generate CRD manifests from your annotated Custom Resource classes, add this dependency to your project:
<dependency>
<groupId>io.fabric8</groupId>
<artifactId>crd-generator-apt</artifactId>
<scope>provided</scope>
</dependency>
The CRD will be generated in target/classes/META-INF/fabric8 (or target/test-classes/META-INF/fabric8 for test scope) with the CRD name suffixed by the generated spec version.
For example, a CR using the java-operator-sdk.io group with a mycrs plural form will result in these files:
mycrs.java-operator-sdk.io-v1.ymlmycrs.java-operator-sdk.io-v1beta1.yml
Note for Quarkus users: If you’re using the quarkus-operator-sdk extension, you don’t need to add any extra dependency for CRD generation - the extension handles this automatically.
2.8 - Dependent resources and workflows
Dependent resources and workflows are features sometimes referenced as higher level abstractions. These two related concepts provides an abstraction over reconciliation of a single resource (Dependent resource) and the orchestration of such resources (Workflows).
2.8.1 - Dependent resources
Motivations and Goals
Most operators need to deal with secondary resources when trying to realize the desired state
described by the primary resource they are in charge of. For example, the Kubernetes-native
Deployment controller needs to manage ReplicaSet instances as part of a Deployment’s
reconciliation process. In this instance, ReplicatSet is considered a secondary resource for
the Deployment controller.
Controllers that deal with secondary resources typically need to perform the following steps, for each secondary resource:
flowchart TD
Start([Start Reconciliation]) --> Compute
Compute[Compute desired secondary<br/>resource based on<br/>primary state] --> Exists
Exists{Secondary<br/>resource<br/>exists?}
Exists -->|No| Create[Create Resource]
Exists -->|Yes| Match
Match{Matches<br/>desired<br/>state?}
Match -->|Yes| Done
Match -->|No| Update[Update Resource]
Create --> Done([Done])
Update --> Done
classDef startEnd fill:#e1f5e1,stroke:#4caf50,stroke-width:2px
classDef compute fill:#e3f2fd,stroke:#2196f3,stroke-width:2px
classDef decision fill:#fff3e0,stroke:#ff9800,stroke-width:2px
classDef action fill:#f3e5f5,stroke:#9c27b0,stroke-width:2px
class Start,Done startEnd
class Compute compute
class Exists,Match decision
class Create,Update actionWhile these steps are not difficult in and of themselves, there are some subtleties that can lead to bugs or sub-optimal code if not done right. As this process is pretty much similar for each dependent resource, it makes sense for the SDK to offer some level of support to remove the boilerplate code associated with encoding these repetitive actions. It should be possible to handle common cases (such as dealing with Kubernetes-native secondary resources) in a semi-declarative way with only a minimal amount of code, JOSDK taking care of wiring everything accordingly.
Moreover, in order for your reconciler to get informed of events on these secondary resources, you need to configure and create event sources and maintain them. JOSDK already makes it rather easy to deal with these, but dependent resources makes it even simpler.
Finally, there are also opportunities for the SDK to transparently add features that are even trickier to get right, such as immediate caching of updated or created resources (so that your reconciler doesn’t need to wait for a cluster roundtrip to continue its work) and associated event filtering (so that something your reconciler just changed doesn’t re-trigger a reconciliation, for example).
Design
DependentResource vs. AbstractDependentResource
The new
DependentResource
interface lies at the core of the design and strives to encapsulate the logic that is required
to reconcile the state of the associated secondary resource based on the state of the primary
one. For most cases, this logic will follow the flow expressed above and JOSDK provides a very
convenient implementation of this logic in the form of the
AbstractDependentResource
class. If your logic doesn’t fit this pattern, though, you can still provide your
own reconcile method implementation. While the benefits of using dependent resources are less
obvious in that case, this allows you to separate the logic necessary to deal with each
secondary resource in its own class that can then be tested in isolation via unit tests. You can
also use the declarative support with your own implementations as we shall see later on.
AbstractDependentResource is designed so that classes extending it specify which functionality
they support by implementing trait interfaces. This design has been selected to express the fact
that not all secondary resources are completely under the control of the primary reconciler:
some dependent resources are only ever created or updated for example and we needed a way to let
JOSDK know when that is the case. We therefore provide trait interfaces: Creator,
Updater and Deleter to express that the DependentResource implementation will provide custom
functionality to create, update and delete its associated secondary resources, respectively. If
these traits are not implemented then parts of the logic described above is never triggered: if
your implementation doesn’t implement Creator, for example, AbstractDependentResource will
never try to create the associated secondary resource, even if it doesn’t exist. It is even
possible to not implement any of these traits and therefore create read-only dependent resources
that will trigger your reconciler whenever a user interacts with them but that are never
modified by your reconciler itself - however note that read-only dependent resources rarely make
sense, as it is usually simpler to register an event source for the target resource.
All subclasses
of AbstractDependentResource
can also implement
the Matcher
interface to customize how the SDK decides whether or not the actual state of the dependent
matches the desired state. This makes it convenient to use these abstract base classes for your
implementation, only customizing the matching logic. Note that in many cases, there is no need
to customize that logic as the SDK already provides convenient default implementations in the
form
of DesiredEqualsMatcher
and
GenericKubernetesResourceMatcher
implementations, respectively. If you want to provide custom logic, you only need your
DependentResource implementation to implement the Matcher interface as below, which shows
how to customize the default matching logic for Kubernetes resources to also consider annotations
and labels, which are ignored by default:
public class MyDependentResource extends KubernetesDependentResource<MyDependent, MyPrimary>
implements Matcher<MyDependent, MyPrimary> {
// your implementation
public Result<MyDependent> match(MyDependent actualResource, MyPrimary primary,
Context<MyPrimary> context) {
return GenericKubernetesResourceMatcher.match(this, actualResource, primary, context, true);
}
}
Batteries included: convenient DependentResource implementations!
JOSDK also offers several other convenient implementations building on top of
AbstractDependentResource that you can use as starting points for your own implementations.
One such implementation is the KubernetesDependentResource class that makes it really easy to work
with Kubernetes-native resources. In this case, you usually only need to provide an implementation
for the desired method to tell JOSDK what the desired state of your secondary resource should
be based on the specified primary resource state.
JOSDK takes care of everything else using default implementations that you can override in case you need more precise control of what’s going on.
We also provide implementations that make it easy to cache
(AbstractExternalDependentResource) or poll for changes in external resources
(PollingDependentResource, PerResourcePollingDependentResource). All the provided
implementations can be found in the io/javaoperatorsdk/operator/processing/dependent package of
the operator-framework-core module.
Sample Kubernetes Dependent Resource
A typical use case, when a Kubernetes resource is fully managed - Created, Read, Updated and
Deleted (or set to be garbage collected). The following example shows how to create a
Deployment dependent resource:
@KubernetesDependent(informer = @Informer(labelSelector = SELECTOR))
class DeploymentDependentResource extends CRUDKubernetesDependentResource<Deployment, WebPage> {
@Override
protected Deployment desired(WebPage webPage, Context<WebPage> context) {
var deploymentName = deploymentName(webPage);
Deployment deployment = loadYaml(Deployment.class, getClass(), "deployment.yaml");
deployment.getMetadata().setName(deploymentName);
deployment.getMetadata().setNamespace(webPage.getMetadata().getNamespace());
deployment.getSpec().getSelector().getMatchLabels().put("app", deploymentName);
deployment.getSpec().getTemplate().getMetadata().getLabels()
.put("app", deploymentName);
deployment.getSpec().getTemplate().getSpec().getVolumes().get(0)
.setConfigMap(new ConfigMapVolumeSourceBuilder().withName(configMapName(webPage)).build());
return deployment;
}
}
The only thing that you need to do is to extend the CRUDKubernetesDependentResource and
specify the desired state for your secondary resources based on the state of the primary one. In
the example above, we’re handling the state of a Deployment secondary resource associated with
a WebPage custom (primary) resource.
The @KubernetesDependent annotation can be used to further configure managed dependent
resource that are extending KubernetesDependentResource.
See the full source code here .
Managed Dependent Resources
As mentioned previously, one goal of this implementation is to make it possible to declaratively
create and wire dependent resources. You can annotate your reconciler with @Dependent
annotations that specify which DependentResource implementation it depends upon.
JOSDK will take the appropriate steps to wire everything together and call your
DependentResource implementations reconcile method before your primary resource is reconciled.
This makes sense in most use cases where the logic associated with the primary resource is
usually limited to status handling based on the state of the secondary resources and the
resources are not dependent on each other. As an alternative, you can also invoke reconciliation explicitly,
event for managed workflows.
See Workflows for more details on how the dependent resources are reconciled.
This behavior and automated handling is referred to as “managed” because the DependentResource
instances are managed by JOSDK, an example of which can be seen below:
@Workflow(
dependents = {
@Dependent(type = ConfigMapDependentResource.class),
@Dependent(type = DeploymentDependentResource.class),
@Dependent(type = ServiceDependentResource.class),
@Dependent(
type = IngressDependentResource.class,
reconcilePrecondition = ExposedIngressCondition.class)
})
public class WebPageManagedDependentsReconciler
implements Reconciler<WebPage>, ErrorStatusHandler<WebPage> {
// omitted code
@Override
public UpdateControl<WebPage> reconcile(WebPage webPage, Context<WebPage> context) {
final var name = context.getSecondaryResource(ConfigMap.class).orElseThrow()
.getMetadata().getName();
webPage.setStatus(createStatus(name));
return UpdateControl.patchStatus(webPage);
}
}
See the full source code of sample here .
Standalone Dependent Resources
It is also possible to wire dependent resources programmatically. In practice this means that the
developer is responsible for initializing and managing the dependent resources as well as calling
their reconcile method. However, this makes it possible for developers to fully customize the
reconciliation process. Standalone dependent resources should be used in cases when the managed use
case does not fit. You can, of course, also use Workflows when managing
resources programmatically.
You can see a commented example of how to do so here.
Creating/Updating Kubernetes Resources
From version 4.4 of the framework the resources are created and updated using Server Side Apply , thus the desired state is simply sent using this approach to update the actual resource.
Comparing desired and actual state (matching)
During the reconciliation of a dependent resource, the desired state is matched with the actual state from the caches. The dependent resource only gets updated on the server if the actual, observed state differs from the desired one. Comparing these two states is a complex problem when dealing with Kubernetes resources because a strict equality check is usually not what is wanted due to the fact that multiple fields might be automatically updated or added by the platform ( by dynamic admission controllers or validation webhooks, for example). Solving this problem in a generic way is therefore a tricky proposition.
JOSDK provides such a generic matching implementation which is used by default: SSABasedGenericKubernetesResourceMatcher This implementation relies on the managed fields used by the Server Side Apply feature to compare only the values of the fields that the controller manages. This ensures that only semantically relevant fields are compared. See javadoc for further details.
JOSDK versions prior to 4.4 were using a different matching algorithm as implemented in GenericKubernetesResourceMatcher.
Since SSA is a complex feature, JOSDK implements a feature flag allowing users to switch between these implementations. See in ConfigurationService.
It is, however, important to note that these implementations are default, generic
implementations that the framework can provide expected behavior out of the box. In many
situations, these will work just fine but it is also possible to provide matching algorithms
optimized for specific use cases. This is easily done by simply overriding
the match(...) method.
It is also possible to bypass the matching logic altogether to simply rely on the server-side
apply mechanism if always sending potentially unchanged resources to the cluster is not an issue.
JOSDK’s matching mechanism allows to spare some potentially useless calls to the Kubernetes API
server. To bypass the matching feature completely, simply override the match method to always
return false, thus telling JOSDK that the actual state never matches the desired one, making
it always update the resources using SSA.
WARNING: Older versions of Kubernetes before 1.25 would create an additional resource version for every SSA update
performed with certain resources - even though there were no actual changes in the stored resource - leading to infinite
reconciliations. This behavior was seen with Secrets using stringData, Ingresses using empty string fields, and
StatefulSets using volume claim templates. The operator framework has added built-in handling for the StatefulSet issue.
If you encounter this issue on an older Kubernetes version, consider changing your desired state, turning off SSA for
that resource, or even upgrading your Kubernetes version. If you encounter it on a newer Kubernetes version, please log
an issue with the JOSDK and with upstream Kubernetes.
Telling JOSDK how to find which secondary resources are associated with a given primary resource
KubernetesDependentResource
automatically maps secondary resource to a primary by owner reference. This behavior can be
customized by implementing
SecondaryToPrimaryMapper
by the dependent resource.
See sample in one of the integration tests here .
Multiple Dependent Resources of Same Type
When dealing with multiple dependent resources of same type, the dependent resource implementation needs to know which specific resource should be targeted when reconciling a given dependent resource, since there could be multiple instances of that type which could possibly be used, each associated with the same primary resource. In this situation, JOSDK automatically selects the appropriate secondary resource matching the desired state associated with the primary resource. This makes sense because the desired state computation already needs to be able to discriminate among multiple related secondary resources to tell JOSDK how they should be reconciled.
There might be cases, though, where it might be problematic to call the desired method several times (for example, because it is costly to do so),
it is always possible to override this automated discrimination using several means (consider in this priority order):
- Override the
targetSecondaryResourceIDmethod, if yourDependentResourceextendsKubernetesDependentResource, where it’s very often possible to easily determine theResourceIDof the secondary resource. This would probably be the easiest solution if you’re working with Kubernetes resources. - Override the
selectTargetSecondaryResourcemethod, if yourDependentResourceextendsAbstractDependentResource. This should be relatively simple to override this method to optimize the matching to your needs. You can see an example of such an implementation in theExternalWithStateDependentResourceclass. - As last resort, you can implement your own
getSecondaryResourcemethod on yourDependentResourceimplementation from scratch.
Sharing an Event Source Between Dependent Resources
Dependent resources usually also provide event sources. When dealing with multiple dependents of the same type, one needs to decide whether these dependent resources should track the same resources and therefore share a common event source, or, to the contrary, track completely separate resources, in which case using separate event sources is advised.
Dependents can therefore reuse existing, named event sources by referring to their name. In the
declarative case, assuming a configMapSource EventSource has already been declared, this
would look as follows:
@Dependent(type = MultipleManagedDependentResourceConfigMap1.class,
useEventSourceWithName = "configMapSource")
A sample is provided as an integration test both: for managed
For standalone cases.
Bulk Dependent Resources
So far, all the cases we’ve considered were dealing with situations where the number of dependent resources needed to reconcile the state expressed by the primary resource is known when writing the code for the operator. There are, however, cases where the number of dependent resources to be created depends on information found in the primary resource.
These cases are covered by the “bulk” dependent resources feature. To create such dependent
resources, your implementation should extend AbstractDependentResource (at least indirectly) and
implement the
BulkDependentResource
interface.
Various examples are provided as integration tests .
To see how bulk dependent resources interact with workflow conditions, please refer to this integration test.
Dependent Resources with External Resource
Dependent resources are designed to manage also non-Kubernetes or external resources.
To implement such dependent you can extend AbstractExternalDependentResource or one of its
subclasses.
For Kubernetes resources we can have nice assumptions, like if there are multiple resources of the same type, we can select the target resource that dependent resource manages based on the name and namespace of the desired resource; or we can use a matcher based SSA in most of the cases if the resource is managed using SSA.
Selecting the target resource
Unfortunately this is not true for external resources. So to make sure we are selecting
the target resources from an event source, we provide a mechanism that helps with that logic.
ResourceIDMapper
maps the resource to and ID and the ID of desired and actual resource is checked for equality.
Your POJO representing an external resource can implement ResourceIDProvider.
The default ResourceIDMapper implementation works on top of resource which implements the ResourceIDProvider:
public interface ResourceIDProvider<T> {
T resourceId();
}
Note that if those approaches does not work for your use case, you can simply
override selectTargetSecondaryResource
method.
Matching external resources
By default, external resources are matched using equality.
So you can override equals of you POJO representing an external resource.
As an alternative you can always override the whole match method to completely customize matching.
External State Tracking Dependent Resources
It is sometimes necessary for a controller to track external (i.e. non-Kubernetes) state to
properly manage some dependent resources. For example, your controller might need to track the
state of a REST API resource, which, after being created, would be refer to by its identifier.
Such identifier would need to be tracked by your controller to properly retrieve the state of
the associated resource and/or assess if such a resource exists. While there are several ways to
support this use case, we recommend storing such information in a dedicated Kubernetes resources
(usually a ConfigMap or a Secret), so that it can be manipulated with common Kubernetes
mechanisms.
This particular use case is supported by the
AbstractExternalDependentResource
class that you can extend to suit your needs, as well as implement the
DependentResourceWithExplicitState
interface. Note that most of the JOSDK-provided dependent resource implementations such as
PollingDependentResource or PerResourcePollingDependentResource already extends
AbstractExternalDependentResource, thus supporting external state tracking out of the box.
See integration test as a sample.
For a better understanding it might be worth to study a sample implementation without dependent resources.
Please also refer to the docs for managing state in general.
Combining Bulk and External State Tracking Dependent Resources
Both bulk and external state tracking features can be combined. In that
case, a separate, state-tracking resource will be created for each bulk dependent resource
created. For example, if three bulk dependent resources associated with external state are created,
three associated ConfigMaps (assuming ConfigMaps are used as a state-tracking resource) will
also be created, one per dependent resource.
See integration test as a sample.
GenericKubernetesResource based Dependent Resources
In rare circumstances resource handling where there is no class representation or just typeless handling might be needed. Fabric8 Client provides GenericKubernetesResource to support that.
For dependent resource this is supported by GenericKubernetesDependentResource . See samples here.
Other Dependent Resource Features
Caching and Event Handling in KubernetesDependentResource
When a Kubernetes resource is created or updated the related informer (more precisely the
InformerEventSource), eventually will receive an event and will cache the up-to-date resource. Typically, though, there might be a small time window when calling thegetResource()of the dependent resource or getting the resource from theEventSourceitself won’t return the just updated resource, in the case where the associated event hasn’t been received from the Kubernetes API. TheKubernetesDependentResourceimplementation, however, addresses this issue, so you don’t have to worry about it by making sure that it or the relatedInformerEventSourcealways return the up-to-date resource.Another feature of
KubernetesDependentResourceis to make sure that if a resource is created or updated during the reconciliation, this particular change, which normally would trigger the reconciliation again (since the resource has changed on the server), will, in fact, not trigger the reconciliation again since we already know the state is as expected. This is a small optimization. For example if during a reconciliation aConfigMapis updated using dependent resources, this won’t trigger a new reconciliation. Such a reconciliation is indeed not needed since the change originated from our reconciler. For this system to work properly, though, it is required that changes are received only by one event source (this is a best practice in general) - so for example if there are two config map dependents, either there should be a shared event source between them, or a label selector on the event sources to select only the relevant events, see in related integration test .
“Read-only” Dependent Resources vs. Event Source
See Integration test for a read-only dependent here.
Some secondary resources only exist as input for the reconciliation process and are never
updated by a controller (they might, and actually usually do, get updated by users interacting
with the resources directly, however). This might be the case, for example, of a ConfigMapthat is
used to configure common characteristics of multiple resources in one convenient place.
In such situations, one might wonder whether it makes sense to create a dependent resource in
this case or simply use an EventSource so that the primary resource gets reconciled whenever a
user changes the resource. Typical dependent resources provide a desired state that the
reconciliation process attempts to match. In the case of so-called read-only dependents, though,
there is no such desired state because the operator / controller will never update the resource
itself, just react to external changes to it. An EventSource would achieve the same result.
Using a dependent resource for that purpose instead of a simple EventSource, however, provides
several benefits:
- dependents can be created declaratively, while an event source would need to be manually created
- if dependents are already used in a controller, it makes sense to unify the handling of all secondary resources as dependents from a code organization perspective
- dependent resources can also interact with the workflow feature, thus allowing the read-only resource to participate in conditions, in particular to decide whether the primary resource needs/can be reconciled using reconcile pre-conditions, block the progression of the workflow altogether with ready post-conditions or have other dependents depend on them, in essence, read-only dependents can participate in workflows just as any other dependents.
2.8.2 - Workflows
Overview
Kubernetes (k8s) does not have the notion of a resource “depending on” on another k8s resource, at least not in terms of the order in which these resources should be reconciled. Kubernetes operators typically need to reconcile resources in order because these resources’ state often depends on the state of other resources or cannot be processed until these other resources reach a given state or some condition holds true for them. Dealing with such scenarios are therefore rather common for operators and the purpose of the workflow feature of the Java Operator SDK (JOSDK) is to simplify supporting such cases in a declarative way. Workflows build on top of the dependent resources feature. While dependent resources focus on how a given secondary resource should be reconciled, workflows focus on orchestrating how these dependent resources should be reconciled.
Workflows describe how as a set of dependent resources (DR) depend on one another, along with the conditions that need to hold true at certain stages of the reconciliation process.
Elements of Workflow
Dependent resource (DR) - are the resources being managed in a given reconciliation logic.
Depends-on relation - a
BDR depends on anotherADR ifBneeds to be reconciled afterA.Reconcile precondition - is a condition on a given DR that needs to be become true before the DR is reconciled. This also allows to define optional resources that would, for example, only be created if a flag in a custom resource
.spechas some specific value.Ready postcondition - is a condition on a given DR to prevent the workflow from proceeding until the condition checking whether the DR is ready holds true
Delete postcondition - is a condition on a given DR to check if the reconciliation of dependents can proceed after the DR is supposed to have been deleted
Activation condition - is a special condition meant to specify under which condition the DR is used in the workflow. A typical use-case for this feature is to only activate some dependents depending on the presence of optional resources / features on the target cluster. Without this activation condition, JOSDK would attempt to register an informer for these optional resources, which would cause an error in the case where the resource is missing. With this activation condition, you can now conditionally register informers depending on whether the condition holds or not. This is a very useful feature when your operator needs to handle different flavors of the platform (e.g. OpenShift vs plain Kubernetes) and/or change its behavior based on the availability of optional resources / features (e.g. CertManager, a specific Ingress controller, etc.).
A generic activation condition is provided out of the box, called CRDPresentActivationCondition
that will prevent the associated dependent resource from being activated if the Custom Resource Definition associated with the dependent’s resource type is not present on the cluster. See related integration test.To have multiple resources of same type with an activation condition is a bit tricky, since you don’t want to have multiple
InformerEventSourcefor the same type, you have to explicitly name the informer for the Dependent Resource (@KubernetesDependent(informerConfig = @InformerConfig(name = "configMapInformer"))) for all resource of same type with activation condition. This will make sure that only one is registered. See details at low level api.
Result conditions
While simple conditions are usually enough, it might happen you want to convey extra information as a result of the
evaluation of the conditions (e.g., to report error messages or because the result of the condition evaluation might be
interesting for other purposes). In this situation, you should implement DetailedCondition instead of Condition and
provide an implementation of the detailedIsMet method, which allows you to return a more detailed Result object via
which you can provide extra information. The DetailedCondition.Result interface provides factory method for your
convenience but you can also provide your own implementation if required.
You can access the results for conditions from the WorkflowResult instance that is returned whenever a workflow is
evaluated. You can access that result from the ManagedWorkflowAndDependentResourceContext accessible from the
reconciliation Context. You can then access individual condition results using the getDependentConditionResult methods. You can see an example of this
in this integration test.
Defining Workflows
Similarly to dependent resources, there are two ways to define workflows, in managed and standalone manner.
Managed
Annotations can be used to declaratively define a workflow for a Reconciler. Similarly to how
things are done for dependent resources, managed workflows execute before the reconcile method
is called. The result of the reconciliation can be accessed via the Context object that is
passed to the reconcile method.
The following sample shows a hypothetical use case to showcase all the elements: the primary
TestCustomResource resource handled by our Reconciler defines two dependent resources, a
Deployment and a ConfigMap. The ConfigMap depends on the Deployment so will be
reconciled after it. Moreover, the Deployment dependent resource defines a ready
post-condition, meaning that the ConfigMap will not be reconciled until the condition defined
by the Deployment becomes true. Additionally, the ConfigMap dependent also defines a
reconcile pre-condition, so it also won’t be reconciled until that condition becomes true. The
ConfigMap also defines a delete post-condition, which means that the workflow implementation
will only consider the ConfigMap deleted until that post-condition becomes true.
@Workflow(dependents = {
@Dependent(name = DEPLOYMENT_NAME, type = DeploymentDependentResource.class,
readyPostcondition = DeploymentReadyCondition.class),
@Dependent(type = ConfigMapDependentResource.class,
reconcilePrecondition = ConfigMapReconcileCondition.class,
deletePostcondition = ConfigMapDeletePostCondition.class,
activationCondition = ConfigMapActivationCondition.class,
dependsOn = DEPLOYMENT_NAME)
})
@ControllerConfiguration
public class SampleWorkflowReconciler implements Reconciler<WorkflowAllFeatureCustomResource>,
Cleaner<WorkflowAllFeatureCustomResource> {
public static final String DEPLOYMENT_NAME = "deployment";
@Override
public UpdateControl<WorkflowAllFeatureCustomResource> reconcile(
WorkflowAllFeatureCustomResource resource,
Context<WorkflowAllFeatureCustomResource> context) {
resource.getStatus()
.setReady(
context.managedWorkflowAndDependentResourceContext() // accessing workflow reconciliation results
.getWorkflowReconcileResult()
.allDependentResourcesReady());
return UpdateControl.patchStatus(resource);
}
@Override
public DeleteControl cleanup(WorkflowAllFeatureCustomResource resource,
Context<WorkflowAllFeatureCustomResource> context) {
// emitted code
return DeleteControl.defaultDelete();
}
}
Standalone
In this mode workflow is built manually using standalone dependent resources . The workflow is created using a builder, that is explicitly called in the reconciler (from web page sample):
@ControllerConfiguration(
labelSelector = WebPageDependentsWorkflowReconciler.DEPENDENT_RESOURCE_LABEL_SELECTOR)
public class WebPageDependentsWorkflowReconciler
implements Reconciler<WebPage>, ErrorStatusHandler<WebPage> {
public static final String DEPENDENT_RESOURCE_LABEL_SELECTOR = "!low-level";
private static final Logger log =
LoggerFactory.getLogger(WebPageDependentsWorkflowReconciler.class);
private KubernetesDependentResource<ConfigMap, WebPage> configMapDR;
private KubernetesDependentResource<Deployment, WebPage> deploymentDR;
private KubernetesDependentResource<Service, WebPage> serviceDR;
private KubernetesDependentResource<Ingress, WebPage> ingressDR;
private final Workflow<WebPage> workflow;
public WebPageDependentsWorkflowReconciler(KubernetesClient kubernetesClient) {
initDependentResources(kubernetesClient);
workflow = new WorkflowBuilder<WebPage>()
.addDependentResource(configMapDR)
.addDependentResource(deploymentDR)
.addDependentResource(serviceDR)
.addDependentResource(ingressDR).withReconcilePrecondition(new ExposedIngressCondition())
.build();
}
@Override
public Map<String, EventSource> prepareEventSources(EventSourceContext<WebPage> context) {
return EventSourceUtils.nameEventSources(
configMapDR.initEventSource(context),
deploymentDR.initEventSource(context),
serviceDR.initEventSource(context),
ingressDR.initEventSource(context));
}
@Override
public UpdateControl<WebPage> reconcile(WebPage webPage, Context<WebPage> context) {
var result = workflow.reconcile(webPage, context);
webPage.setStatus(createStatus(result));
return UpdateControl.patchStatus(webPage);
}
// omitted code
}
Workflow Execution
This section describes how a workflow is executed in details, how the ordering is determined and
how conditions and errors affect the behavior. The workflow execution is divided in two parts
similarly to how Reconciler and Cleaner behavior are separated.
Cleanup is
executed if a resource is marked for deletion.
Common Principles
- As complete as possible execution - when a workflow is reconciled, it tries to reconcile as many resources as possible. Thus, if an error happens or a ready condition is not met for a resources, all the other independent resources will be still reconciled. This is the opposite to a fail-fast approach. The assumption is that eventually in this way the overall state will converge faster towards the desired state than would be the case if the reconciliation was aborted as soon as an error occurred.
- Concurrent reconciliation of independent resources - the resources which doesn’t depend on others are processed concurrently. The level of concurrency is customizable, could be set to one if required. By default, workflows use the executor service from ConfigurationService
Reconciliation
This section describes how a workflow is executed, considering first which rules apply, then demonstrated using examples:
Rules
- A workflow is a Directed Acyclic Graph (DAG) build from the DRs and their associated
depends-onrelations. - Root nodes, i.e. nodes in the graph that do not depend on other nodes are reconciled first, in a parallel manner.
- A DR is reconciled if it does not depend on any other DRs, or ALL the DRs it depends on are
reconciled and ready. If a DR defines a reconcile pre-condition and/or an activation condition,
then these condition must become
truebefore the DR is reconciled. - A DR is considered ready if it got successfully reconciled and any ready post-condition it
might define is
true. - If a DR’s reconcile pre-condition is not met, this DR is deleted. All the DRs that depend
on the dependent resource are also recursively deleted. This implies that
DRs are deleted in reverse order compared the one in which they are reconciled. The reason
for this behavior is (Will make a more detailed blog post about the design decision, much deeper
than the reference documentation)
The reasoning behind this behavior is as follows: a DR with a reconcile pre-condition is only
reconciled if the condition holds
true. This means that if the condition isfalseand the resource didn’t exist already, then the associated resource would not be created. To ensure idempotency (i.e. with the same input state, we should have the same output state), from this follows that if the condition doesn’t holdtrueanymore, the associated resource needs to be deleted because the resource shouldn’t exist/have been created. - If a DR’s activation condition is not met, it won’t be reconciled or deleted. If other DR’s depend on it, those will be recursively deleted in a way similar to reconcile pre-conditions. Event sources for a dependent resource with activation condition are registered/de-registered dynamically, thus during the reconciliation.
- For a DR to be deleted by a workflow, it needs to implement the
Deleterinterface, in which case itsdeletemethod will be called, unless it also implements theGarbageCollectedinterface. If a DR doesn’t implementDeleterit is considered as automatically deleted. If a delete post-condition exists for this DR, it needs to becometruefor the workflow to consider the DR as successfully deleted.
Samples
Notation: The arrows depicts reconciliation ordering, thus following the reverse direction of thedepends-on relation:
1 --> 2 mean DR 2 depends-on DR 1.
Reconcile Sample
stateDiagram-v2 1 --> 2 1 --> 3 2 --> 4 3 --> 4
- Root nodes (i.e. nodes that don’t depend on any others) are reconciled first. In this example,
DR
1is reconciled first since it doesn’t depend on others. After that both DR2and3are reconciled concurrently, then DR4once both are reconciled successfully. - If DR
2had a ready condition and if it evaluated to asfalse, DR4would not be reconciled. However1,2and3would be. - If
1had afalseready condition, neither2,3or4would be reconciled. - If
2’s reconciliation resulted in an error,4would not be reconciled, but3would be (and1as well, of course).
Sample with Reconcile Precondition
stateDiagram-v2 1 --> 2 1 --> 3 3 --> 4 3 --> 5
- If
3has a reconcile pre-condition that is not met,1and2would be reconciled. However, DR3,4,5would be deleted:4and5would be deleted concurrently but3would only be deleted if4and5were deleted successfully (i.e. without error) and all existing delete post-conditions were met. - If
5had a delete post-condition that wasfalse,3would not be deleted but4would still be because they don’t depend on one another. - Similarly, if
5’s deletion resulted in an error,3would not be deleted but4would be.
Cleanup
Cleanup works identically as delete for resources in reconciliation in case reconcile pre-condition is not met, just for the whole workflow.
Rules
- Delete is called on a DR if there is no DR that depends on it
- If a DR has DRs that depend on it, it will only be deleted if all these DRs are successfully
deleted without error and any delete post-condition is
true. - A DR is “manually” deleted (i.e. it’s
Deleter.deletemethod is called) if it implements theDeleterinterface but does not implementGarbageCollected. If a DR does not implementDeleterinterface, it is considered as deleted automatically.
Sample
stateDiagram-v2 1 --> 2 1 --> 3 2 --> 4 3 --> 4
- The DRs are deleted in the following order:
4is deleted first, then2and3are deleted concurrently, and, only after both are successfully deleted,1is deleted. - If
2had a delete post-condition that wasfalse,1would not be deleted.4and3would be deleted. - If
2was in error, DR1would not be deleted. DR4and3would be deleted. - if
4was in error, no other DR would be deleted.
Error Handling
As mentioned before if an error happens during a reconciliation, the reconciliation of other dependent resources will still happen, assuming they don’t depend on the one that failed. If case multiple DRs fail, the workflow would throw an ‘AggregatedOperatorException’ containing all the related exceptions.
The exceptions can be handled
by ErrorStatusHandler
Waiting for the actual deletion of Kubernetes Dependent Resources
Let’s consider a case when a Kubernetes Dependent Resources (KDR) depends on another resource, on cleanup
the resources will be deleted in reverse order, thus the KDR will be deleted first.
However, the workflow implementation currently simply asks the Kubernetes API server to delete the resource. This is,
however, an asynchronous process, meaning that the deletion might not occur immediately, in particular if the resource
uses finalizers that block the deletion or if the deletion itself takes some time. From the SDK’s perspective, though,
the deletion has been requested and it moves on to other tasks without waiting for the resource to be actually deleted
from the server (which might never occur if it uses finalizers which are not removed).
In situations like these, if your logic depends on resources being actually removed from the cluster before a
cleanup workflow can proceed correctly, you need to block the workflow progression using a delete post-condition that
checks that the resource is actually removed or that it, at least, doesn’t have any finalizers any longer. JOSDK
provides such a delete post-condition implementation in the form of
KubernetesResourceDeletedCondition
Also, check usage in an integration test.
In such cases the Kubernetes Dependent Resource should extend CRUDNoGCKubernetesDependentResource
and NOT CRUDKubernetesDependentResource since otherwise the Kubernetes Garbage Collector would delete the resources.
In other words if a Kubernetes Dependent Resource depends on another dependent resource, it should not implement
GargageCollected interface, otherwise the deletion order won’t be guaranteed.
Explicit Managed Workflow Invocation
Managed workflows, i.e. ones that are declared via annotations and therefore completely managed by JOSDK, are reconciled before the primary resource. Each dependent resource that can be reconciled (according to the workflow configuration) will therefore be reconciled before the primary reconciler is called to reconcile the primary resource. There are, however, situations where it would be be useful to perform additional steps before the workflow is reconciled, for example to validate the current state, execute arbitrary logic or even skip reconciliation altogether. Explicit invocation of managed workflow was therefore introduced to solve these issues.
To use this feature, you need to set the explicitInvocation field to true on the @Workflow annotation and then
call the reconcileManagedWorkflow method from the ManagedWorkflowAndDependentResourceContext retrieved from the reconciliation Context provided as part of your primary
resource reconciler reconcile method arguments.
See related integration test for more details.
For cleanup, if the Cleaner interface is implemented, the cleanupManageWorkflow() needs to be called explicitly.
However, if Cleaner interface is not implemented, it will be called implicitly.
See
related integration test.
While nothing prevents calling the workflow multiple times in a reconciler, it isn’t typical or even recommended to do
so. Conversely, if explicit invocation is requested but reconcileManagedWorkflow is not called in the primary resource
reconciler, the workflow won’t be reconciled at all.
Notes and Caveats
- Delete is almost always called on every resource during the cleanup. However, it might be the case that the resources were already deleted in a previous run, or not even created. This should not be a problem, since dependent resources usually cache the state of the resource, so are already aware that the resource does not exist and that nothing needs to be done if delete is called.
- If a resource has owner references, it will be automatically deleted by the Kubernetes garbage
collector if the owner resource is marked for deletion. This might not be desirable, to make
sure that delete is handled by the workflow don’t use garbage collected kubernetes dependent
resource, use for
example
CRUDNoGCKubernetesDependentResource. - No state is persisted regarding the workflow execution. Every reconciliation causes all the resources to be reconciled again, in other words the whole workflow is again evaluated.
2.9 - Architecture and Internals
This document provides an overview of the Java Operator SDK’s internal structure and components to help developers understand and contribute to the project. While not a comprehensive reference, it introduces core concepts that should make other components easier to understand.
The Big Picture and Core Components

An Operator is a set of independent controllers.
The Controller class is an internal class managed by the framework and typically shouldn’t be interacted with directly. It manages all processing units involved with reconciling a single type of Kubernetes resource.
Core Components
- Reconciler - The primary entry point for developers to implement reconciliation logic
- EventSource - Represents a source of events that might trigger reconciliation
- EventSourceManager - Aggregates all event sources for a controller and manages their lifecycle
- ControllerResourceEventSource - Central event source that watches primary resources associated with a given controller for changes, propagates events and caches state
- EventProcessor - Processes incoming events sequentially per resource while allowing concurrent overall processing. Handles rescheduling and retrying
- ReconcilerDispatcher - Dispatches requests to appropriate
Reconcilermethods and handles reconciliation results, making necessary Kubernetes API calls
Typical Workflow
A typical workflow follows these steps:
- Event Generation: An
EventSourceproduces an event and propagates it to theEventProcessor - Resource Reading: The resource associated with the event is read from the internal cache
- Reconciliation Submission: If the resource isn’t already being processed, a reconciliation request is submitted to the executor service in a different thread (encapsulated in a
ControllerExecutioninstance) - Dispatching: The
ReconcilerDispatcheris called, which dispatches the call to the appropriateReconcilermethod with all required information - Reconciler Execution: Once the
Reconcilercompletes, theReconcilerDispatchermakes appropriate Kubernetes API server calls based on the returned result - Finalization: The
EventProcessoris called back to finalize execution and update the controller’s state - Rescheduling Check: The
EventProcessorchecks if the request needs rescheduling or retrying, and whether subsequent events were received for the same resource - Completion: When no further action is needed, event processing is finished
3 - Integration Test Index
This document provides an index of all integration tests annotated with @Sample.
These serve also as samples for various use cases. You are encouraged to improve both the tests and/or descriptions.
Contents
Base API
- Cleanup handler for built-in Kubernetes resources
- Dynamically Changing Watched Namespaces
- Implementing Cleanup Logic with Cleaner Interface
- Cleanup Finalizer Removal Without Conflicts
- Cluster-scoped resource reconciliation
- Concurrent Finalizer Removal by Multiple Reconcilers
- Event filtering for create and update operations
- Event Filtering with Previous Annotation Disabled
- Reconciling Non-Custom Kubernetes Resources with Status Updates
- Dynamic Generic Event Source Registration
- Error Status Handler for Failed Reconciliations
- Custom Event Source for Periodic Reconciliation
- Basic Expectation Pattern with AllEvents Trigger
- Expectation Pattern with Periodic Cleanup
- Filtering Events for Primary and Secondary Resources
- Working with GenericKubernetesResource for Dynamic Resource Types
- Graceful Operator Shutdown with Reconciliation Timeout
- Using Informer Event Source to Watch Secondary Resources
- Watching resources in a remote Kubernetes cluster
- Operator Startup with Informer Errors
- Label Selector for Custom Resource Filtering
- Leader election with namespace change handling
- Leader Election with Insufficient Permissions
- Manually managing observedGeneration in status
- Maximum Reconciliation Interval Configuration
- Maximum Reconciliation Interval After Retry
- Multiple reconcilers for the same resource type
- Managing Multiple Secondary Event Sources
- Handling Multiple CRD Versions
- Skipping status updates when next reconciliation is imminent
- Patching resource and status without Server-Side Apply
- Patching resource and status with Server-Side Apply
- Patching Resources with Server-Side Apply (SSA)
- Per-resource polling event source implementation
- Using Primary Indexer for Secondary Resource Mapping
- Primary to Secondary Resource Mapping
- Issues When Primary-to-Secondary Mapper Is Missing
- Rate Limiting Reconciliation Executions
- Automatic Retry for Failed Reconciliations
- Maximum Retry Attempts Configuration
- Basic reconciler execution
- Server-Side Apply Finalizer Field Manager Issue
- Server-Side Apply Finalizer Removal on Spec Update
- Accessing Secondary Resources During Operator Startup
- Status patch caching for consistency
- Status Patching Without Optimistic Locking for Non-SSA
- Migrating Status Patching from Non-SSA to SSA
- Status Update Locking and Concurrency Control
- Status Subresource Updates
- Unmodifiable Parts in Dependent Resources
- Update Status in Cleanup and Reschedule
Dependent Resources
- Bulk Dependent Resource Deleter Implementation
- Bulk Dependent Resources with Ready Conditions
- Managing External Bulk Resources
- Bulk Dependent Resources with Managed Workflow
- Read-Only Bulk Dependent Resources
- Standalone Bulk Dependent Resources
- Cleanup handlers for managed dependent resources
- Create-Only Dependent Resources with Server-Side Apply
- Annotation-Based Secondary Resource Mapping for Dependents
- Custom Annotation Keys for Resource Mapping
- Dependent Resources in Different Namespaces
- Filtering Reconciliation Triggers from Dependent Resources
- Event filtering for dependent resource operations
- Reusing Dependent Resource Instances Across Tests
- Dependent Resources with Cross-References
- Server-Side Apply (SSA) with Dependent Resources
- Migrating Dependent Resources from Legacy to SSA
- External State Tracking in Dependent Resources
- Managing External Resources with Persistent State
- Bulk External State Management with Persistent State
- Generic Kubernetes Dependent Resource (Managed)
- Generic Kubernetes Resource as Standalone Dependent
- Kubernetes Native Garbage Collection for Dependent Resources
- Managing Multiple Dependent Resources
- Multiple Dependents of Same Type Without Discriminator
- Multiple Managed Dependents of Same Type with Multi-Informer
- Multiple Managed Dependents of Same Type Without Discriminator
- Managing Multiple Dependent Resources of the Same Type
- Multiple Managed External Dependents of Same Type
- Dependent Resource Shared by Multiple Owners
- Blocking Previous Annotation for Specific Resource Types
- Primary Resource Indexer with Dependent Resources
- Primary to Secondary Dependent Resource
- Operator restart and state recovery
- Strict matching for Service resources
- Handling special Kubernetes resources without spec
- Using Legacy Resource Matcher with SSA
- Standalone Dependent Resources
- Sanitizing StatefulSet desired state for SSA
Workflows
- Complex Workflow with Multiple Dependents
- Workflow Activation Based on CRD Presence
- Workflow Functions on Vanilla Kubernetes Despite Inactive Resources
- Managed Dependent Delete Condition
- Multiple Dependents with Activation Conditions
- Ordered Managed Dependent Resources
- Workflow Activation Cleanup
- Workflow Activation Condition
- Comprehensive workflow with reconcile and delete conditions
- Explicit Workflow Cleanup Invocation
- Workflow Explicit Invocation
- Dynamic Workflow Activation and Deactivation
- Silent Workflow Exception Handling in Reconciler
Base API
BuiltInResourceCleanerIT
Cleanup handler for built-in Kubernetes resources
Demonstrates how to implement cleanup handlers (finalizers) for built-in Kubernetes resources like Service and Pod. These resources don’t use generation the same way as custom resources, so this sample shows the proper approach to handle their lifecycle and cleanup logic.
Package: io.javaoperatorsdk.operator.baseapi.builtinresourcecleaner
ChangeNamespaceIT
Dynamically Changing Watched Namespaces
Demonstrates how to dynamically change the set of namespaces that an operator watches at runtime. This feature allows operators to add or remove namespaces from their watch list, including switching between specific namespaces and watching all namespaces. The test verifies that resources in newly added namespaces are reconciled and resources in removed namespaces are no longer watched.
Package: io.javaoperatorsdk.operator.baseapi.changenamespace
CleanerForReconcilerIT
Implementing Cleanup Logic with Cleaner Interface
Demonstrates how to implement cleanup logic for custom resources using the Cleaner interface. When a reconciler implements Cleaner, the framework automatically adds a finalizer to resources and calls the cleanup method when the resource is deleted. This pattern is useful for cleaning up external resources or performing custom deletion logic. The test verifies finalizer handling, cleanup execution, and the ability to reschedule cleanup operations.
Package: io.javaoperatorsdk.operator.baseapi.cleanerforreconciler
CleanupConflictIT
Cleanup Finalizer Removal Without Conflicts
Tests that finalizers are removed correctly during cleanup without causing conflicts, even when multiple finalizers are present and removed concurrently. This verifies the operator’s ability to handle finalizer updates safely during resource deletion.
Package: io.javaoperatorsdk.operator.baseapi.cleanupconflict
ClusterScopedResourceIT
Cluster-scoped resource reconciliation
Demonstrates how to reconcile cluster-scoped custom resources (non-namespaced). This test shows CRUD operations on cluster-scoped resources and verifies that dependent resources are created, updated, and properly cleaned up when the primary resource is deleted.
Package: io.javaoperatorsdk.operator.baseapi.clusterscopedresource
ConcurrentFinalizerRemovalIT
Concurrent Finalizer Removal by Multiple Reconcilers
Demonstrates safe concurrent finalizer removal when multiple reconcilers manage the same resource with different finalizers. Tests that finalizers can be removed concurrently without conflicts or race conditions, ensuring proper cleanup even when multiple controllers are involved.
Package: io.javaoperatorsdk.operator.baseapi.concurrentfinalizerremoval
CreateUpdateInformerEventSourceEventFilterIT
Event filtering for create and update operations
Shows how to configure event filters on informer event sources to control which create and update events trigger reconciliation. This is useful for preventing unnecessary reconciliation loops when dependent resources are modified by the controller itself.
Package: io.javaoperatorsdk.operator.baseapi.createupdateeventfilter
PreviousAnnotationDisabledIT
Event Filtering with Previous Annotation Disabled
Tests event filtering behavior when the previous annotation feature for dependent resources is disabled. Verifies that update events are properly received and handled even without the annotation tracking mechanism that compares previous resource states.
Package: io.javaoperatorsdk.operator.baseapi.createupdateeventfilter
KubernetesResourceStatusUpdateIT
Reconciling Non-Custom Kubernetes Resources with Status Updates
Demonstrates how to reconcile standard Kubernetes resources (like Deployments) instead of custom resources, and how to update their status subresource. This pattern is useful when building operators that manage native Kubernetes resources rather than custom resource definitions. The test verifies that the operator can watch, reconcile, and update the status of a Deployment resource.
Package: io.javaoperatorsdk.operator.baseapi.deployment
DynamicGenericEventSourceRegistrationIT
Dynamic Generic Event Source Registration
Demonstrates dynamic registration of generic event sources during runtime. The test verifies that event sources can be dynamically added to a reconciler and properly trigger reconciliation when the associated resources change, enabling flexible event source management.
Package: io.javaoperatorsdk.operator.baseapi.dynamicgenericeventsourceregistration
ErrorStatusHandlerIT
Error Status Handler for Failed Reconciliations
Demonstrates how to implement error status handlers that update resource status when reconciliations fail. The test verifies that error messages are properly recorded in the resource status after each failed retry attempt. This provides visibility into reconciliation failures and helps with debugging operator issues.
Package: io.javaoperatorsdk.operator.baseapi.errorstatushandler
EventSourceIT
Custom Event Source for Periodic Reconciliation
Demonstrates how to implement custom event sources that trigger reconciliation on a periodic basis. The test verifies that reconciliations are triggered at regular intervals by a timer-based event source. This enables operators to perform periodic checks or updates independent of resource changes.
Package: io.javaoperatorsdk.operator.baseapi.event
ExpectationIT
Basic Expectation Pattern with AllEvents Trigger
Demonstrates the basic expectation pattern using ExpectationManager with triggerReconcilerOnAllEvents = true. This pattern allows reconcilers to wait for specific conditions to be met (like a Deployment having 3 ready replicas) before proceeding with status updates. The test shows both successful expectation fulfillment and timeout handling. Requires @ControllerConfiguration(triggerReconcilerOnAllEvents = true) for proper operation.
Package: io.javaoperatorsdk.operator.baseapi.expectation.onallevent
PeriodicCleanerExpectationIT
Expectation Pattern with Periodic Cleanup
Demonstrates the PeriodicCleanerExpectationManager pattern which provides automatic cleanup of stale expectations. This pattern works without requiring @ControllerConfiguration(triggerReconcilerOnAllEvents = true) and automatically cleans up stale expectations periodically (default: 1 minute). This is ideal for ‘set and forget’ scenarios where you want the same expectation API and functionality as the regular ExpectationManager but with automatic lifecycle management.
Package: io.javaoperatorsdk.operator.baseapi.expectation.periodicclean
FilterIT
Filtering Events for Primary and Secondary Resources
Demonstrates how to implement event filters for both primary custom resources and secondary dependent resources. The test verifies that resource updates matching specific filter criteria are ignored and don’t trigger reconciliation. This helps reduce unnecessary reconciliation executions and improve operator efficiency.
Package: io.javaoperatorsdk.operator.baseapi.filter
GenericKubernetesResourceHandlingIT
Working with GenericKubernetesResource for Dynamic Resource Types
Demonstrates how to use GenericKubernetesResource to work with Kubernetes resources dynamically without requiring compile-time type definitions. This approach is useful when building operators that need to manage arbitrary Kubernetes resources or when the resource types are not known at compile time. The test shows how to handle generic resources as dependent resources in a reconciler.
Package: io.javaoperatorsdk.operator.baseapi.generickubernetesresourcehandling
GracefulStopIT
Graceful Operator Shutdown with Reconciliation Timeout
Demonstrates how to configure graceful shutdown behavior with reconciliation termination timeouts. The test verifies that in-progress reconciliations are allowed to complete when the operator stops. This ensures clean shutdown without interrupting ongoing reconciliation work.
Package: io.javaoperatorsdk.operator.baseapi.gracefulstop
InformerEventSourceIT
Using Informer Event Source to Watch Secondary Resources
Demonstrates how to use InformerEventSource to watch changes in secondary resources (ConfigMaps) and trigger reconciliation when those resources are created, updated, or deleted. The test verifies that the reconciler responds to ConfigMap changes and updates the primary resource status accordingly.
Package: io.javaoperatorsdk.operator.baseapi.informereventsource
InformerRemoteClusterIT
Watching resources in a remote Kubernetes cluster
Demonstrates how to configure an informer event source to watch resources in a different Kubernetes cluster from where the operator is running. This enables multi-cluster scenarios where an operator in one cluster manages resources in another cluster.
Package: io.javaoperatorsdk.operator.baseapi.informerremotecluster
InformerErrorHandlerStartIT
Operator Startup with Informer Errors
Demonstrates that the operator can start successfully even when informers encounter errors during startup, such as insufficient access rights. By setting stopOnInformerErrorDuringStartup to false, the operator gracefully handles permission errors and continues initialization, allowing it to operate with partial access.
Package: io.javaoperatorsdk.operator.baseapi.informerstarterror
LabelSelectorIT
Label Selector for Custom Resource Filtering
Demonstrates how to configure label selectors to filter which custom resources an operator watches. The test verifies that only resources with matching labels trigger reconciliation. This allows operators to selectively manage a subset of custom resources based on their labels.
Package: io.javaoperatorsdk.operator.baseapi.labelselector
LeaderElectionChangeNamespaceIT
Leader election with namespace change handling
Tests that when an operator is not elected as leader, changing the watched namespaces does not start processing. This ensures that only the leader operator actively reconciles resources, preventing conflicts in multi-instance deployments with leader election.
Package: io.javaoperatorsdk.operator.baseapi.leaderelectionchangenamespace
LeaderElectionPermissionIT
Leader Election with Insufficient Permissions
Verifies that the operator fails gracefully when leader election is configured but the service account lacks permissions to access lease resources. This test ensures proper error handling and messaging when RBAC permissions are insufficient for leader election functionality.
Package: io.javaoperatorsdk.operator.baseapi.leaderelectionpermission
ManualObservedGenerationIT
Manually managing observedGeneration in status
Shows how to manually track and update the observedGeneration field in status to indicate which generation of the resource spec has been successfully processed. This is useful for providing clear feedback to users about reconciliation progress.
Package: io.javaoperatorsdk.operator.baseapi.manualobservedgeneration
MaxIntervalIT
Maximum Reconciliation Interval Configuration
Demonstrates how to configure a maximum interval for periodic reconciliation triggers. The test verifies that reconciliation is automatically triggered at the configured interval even when there are no resource changes, enabling periodic validation and drift detection.
Package: io.javaoperatorsdk.operator.baseapi.maxinterval
MaxIntervalAfterRetryIT
Maximum Reconciliation Interval After Retry
Tests that reconciliation is repeatedly triggered based on the maximum interval setting even after retries. This ensures periodic reconciliation continues at the configured maximum interval, maintaining eventual consistency regardless of retry attempts.
Package: io.javaoperatorsdk.operator.baseapi.maxintervalafterretry
MultipleReconcilerSameTypeIT
Multiple reconcilers for the same resource type
Demonstrates how to register multiple reconcilers for the same custom resource type, with each reconciler handling different resources based on label selectors or other criteria. This enables different processing logic for different subsets of the same resource type.
Package: io.javaoperatorsdk.operator.baseapi.multiplereconcilersametype
MultipleSecondaryEventSourceIT
Managing Multiple Secondary Event Sources
Demonstrates how to configure and use multiple secondary event sources for a single reconciler. The test verifies that the reconciler is triggered by changes to different secondary resources and handles events from multiple sources correctly, including periodic event sources.
Package: io.javaoperatorsdk.operator.baseapi.multiplesecondaryeventsource
MultiVersionCRDIT
Handling Multiple CRD Versions
Demonstrates how to work with Custom Resource Definitions that have multiple API versions. The test shows how to configure multiple reconcilers for different versions of the same CRD, handle version-specific schemas, and deal with incompatible version conversions. It also demonstrates error handling through InformerStoppedHandler when deserialization fails due to schema incompatibilities between versions.
Package: io.javaoperatorsdk.operator.baseapi.multiversioncrd
NextReconciliationImminentIT
Skipping status updates when next reconciliation is imminent
Shows how to use the nextReconciliationImminent flag to skip status updates when another reconciliation event is already pending. This optimization prevents unnecessary status patch operations when rapid consecutive reconciliations occur.
Package: io.javaoperatorsdk.operator.baseapi.nextreconciliationimminent
PatchResourceAndStatusNoSSAIT
Patching resource and status without Server-Side Apply
Demonstrates how to patch both the primary resource metadata/spec and status subresource using traditional JSON merge patch instead of Server-Side Apply. This shows the legacy approach for updating resources when SSA is disabled.
Package: io.javaoperatorsdk.operator.baseapi.patchresourceandstatusnossa
PatchResourceAndStatusWithSSAIT
Patching resource and status with Server-Side Apply
Demonstrates how to use Server-Side Apply (SSA) to patch both the primary resource and its status subresource. SSA provides better conflict resolution and field management tracking compared to traditional merge patches, making it the recommended approach for resource updates.
Package: io.javaoperatorsdk.operator.baseapi.patchresourcewithssa
PatchResourceWithSSAIT
Patching Resources with Server-Side Apply (SSA)
Demonstrates how to use Server-Side Apply (SSA) for patching primary resources in Kubernetes. The test verifies that the reconciler can patch resources using SSA, which provides better conflict resolution and field management compared to traditional update approaches, including proper handling of managed fields.
Package: io.javaoperatorsdk.operator.baseapi.patchresourcewithssa
PerResourcePollingEventSourceIT
Per-resource polling event source implementation
Shows how to implement a per-resource polling event source where each primary resource has its own polling schedule to fetch external state. This is useful for integrating with external systems that don’t support event-driven notifications.
Package: io.javaoperatorsdk.operator.baseapi.perresourceeventsource
PrimaryIndexerIT
Using Primary Indexer for Secondary Resource Mapping
Demonstrates how to use primary indexers to efficiently map secondary resources back to their primary resources. When a secondary resource (like a ConfigMap) changes, the primary indexer allows the framework to determine which primary resources should be reconciled. This pattern enables efficient one-to-many and many-to-many relationships between primary and secondary resources without polling or full scans.
Package: io.javaoperatorsdk.operator.baseapi.primaryindexer
PrimaryToSecondaryIT
Primary to Secondary Resource Mapping
Demonstrates many-to-one mapping between primary and secondary resources where multiple primary resources can reference the same secondary resource. The test verifies that changes in the secondary resource trigger reconciliation of all related primary resources, enabling shared resource patterns.
Package: io.javaoperatorsdk.operator.baseapi.primarytosecondary
PrimaryToSecondaryMissingIT
Issues When Primary-to-Secondary Mapper Is Missing
Demonstrates the problems that occur when accessing secondary resources without a proper PrimaryToSecondaryMapper configured. The test shows that accessing secondary resources through the context fails without the mapper, while direct cache access works as a workaround, highlighting the importance of proper mapper configuration.
Package: io.javaoperatorsdk.operator.baseapi.primarytosecondary
RateLimitIT
Rate Limiting Reconciliation Executions
Demonstrates how to implement rate limiting to control how frequently reconciliations execute. The test shows that multiple rapid resource updates are batched and executed at a controlled rate. This prevents overwhelming the system when resources change frequently.
Package: io.javaoperatorsdk.operator.baseapi.ratelimit
RetryIT
Automatic Retry for Failed Reconciliations
Demonstrates how to configure automatic retry logic for reconciliations that fail temporarily. The test shows that failed executions are automatically retried with configurable intervals and max attempts. After a specified number of retries, the reconciliation succeeds and updates the resource status accordingly.
Package: io.javaoperatorsdk.operator.baseapi.retry
RetryMaxAttemptIT
Maximum Retry Attempts Configuration
Demonstrates how to configure a maximum number of retry attempts for failed reconciliations. The test verifies that the operator stops retrying after reaching the configured maximum attempts. This prevents infinite retry loops when reconciliations consistently fail.
Package: io.javaoperatorsdk.operator.baseapi.retry
ReconcilerExecutorIT
Basic reconciler execution
Demonstrates the basic reconciler execution flow including resource creation, status updates, and cleanup. This test verifies that a reconciler can create dependent resources (ConfigMap), update status, and properly handle cleanup when resources are deleted.
Package: io.javaoperatorsdk.operator.baseapi.simple
SSAFinalizerIssueIT
Server-Side Apply Finalizer Field Manager Issue
Demonstrates a potential issue with Server-Side Apply (SSA) when adding finalizers. When a resource is created with the same field manager used by the controller, adding a finalizer can unexpectedly remove other spec fields, showcasing field manager ownership conflicts in SSA.
Package: io.javaoperatorsdk.operator.baseapi.ssaissue.finalizer
SSASpecUpdateIT
Server-Side Apply Finalizer Removal on Spec Update
Demonstrates an issue with Server-Side Apply (SSA) where updating the resource spec without explicitly including the finalizer causes the finalizer to be removed. This highlights the importance of including all desired fields when using SSA to avoid unintended field removal.
Package: io.javaoperatorsdk.operator.baseapi.ssaissue.specupdate
StartupSecondaryAccessIT
Accessing Secondary Resources During Operator Startup
Verifies that reconcilers can properly access all secondary resources during operator startup, even when a large number of secondary resources exist. The test ensures that the informer cache is fully synchronized before reconciliation begins, allowing access to all related resources.
Package: io.javaoperatorsdk.operator.baseapi.startsecondaryaccess
StatusPatchCacheIT
Status patch caching for consistency
Demonstrates how the framework caches status patches to ensure consistency when status is updated frequently. The cache guarantees that status values are monotonically increasing and always reflect the most recent state, even with rapid successive updates.
Package: io.javaoperatorsdk.operator.baseapi.statuscache
StatusPatchNotLockingForNonSSAIT
Status Patching Without Optimistic Locking for Non-SSA
Tests status update behavior when not using Server-Side Apply (SSA), verifying that optimistic locking is not enforced on status patches. The test also demonstrates proper field deletion when values are set to null, ensuring correct status management without SSA optimistic locking.
Package: io.javaoperatorsdk.operator.baseapi.statuspatchnonlocking
StatusPatchSSAMigrationIT
Migrating Status Patching from Non-SSA to SSA
Demonstrates the process and challenges of migrating status patching from traditional update methods to Server-Side Apply (SSA). Tests show a known Kubernetes issue where field deletion doesn’t work correctly during migration, and provides a workaround by removing managed field entries from the previous update method.
Package: io.javaoperatorsdk.operator.baseapi.statuspatchnonlocking
StatusUpdateLockingIT
Status Update Locking and Concurrency Control
Demonstrates how the framework handles concurrent status updates and ensures no optimistic locking conflicts occur when updating status subresources. The test verifies that status updates can proceed independently of spec updates without causing version conflicts or requiring retries.
Package: io.javaoperatorsdk.operator.baseapi.statusupdatelocking
SubResourceUpdateIT
Status Subresource Updates
Demonstrates how to properly update the status subresource of custom resources. The test verifies that status updates are handled correctly without triggering unnecessary reconciliations, and that concurrent spec and status updates are managed properly with optimistic locking and retry mechanisms.
Package: io.javaoperatorsdk.operator.baseapi.subresource
UnmodifiableDependentPartIT
Unmodifiable Parts in Dependent Resources
Demonstrates how to preserve certain parts of a dependent resource from being modified during updates while allowing other parts to change. This test shows that initial data can be marked as unmodifiable and will remain unchanged even when the primary resource spec is updated, enabling partial update control.
Package: io.javaoperatorsdk.operator.baseapi.unmodifiabledependentpart
UpdateStatusInCleanupAndRescheduleIT
Update Status in Cleanup and Reschedule
Tests the ability to update resource status during cleanup and reschedule the cleanup operation. This demonstrates that cleanup methods can perform status updates and request to be called again after a delay, enabling multi-step cleanup processes with status tracking.
Package: io.javaoperatorsdk.operator.baseapi.updatestatusincleanupandreschedule
Dependent Resources
BulkDependentDeleterIT
Bulk Dependent Resource Deleter Implementation
Demonstrates implementation of a bulk dependent resource with custom deleter logic. This test extends BulkDependentTestBase to verify that bulk dependent resources can implement custom deletion strategies, managing multiple resources efficiently during cleanup operations.
Package: io.javaoperatorsdk.operator.dependent.bulkdependent
BulkDependentWithConditionIT
Bulk Dependent Resources with Ready Conditions
Tests bulk dependent resources with preconditions that control when reconciliation occurs. This demonstrates using ready conditions to ensure bulk operations only execute when the primary resource is in the appropriate state, coordinating complex multi-resource management.
Package: io.javaoperatorsdk.operator.dependent.bulkdependent.condition
BulkExternalDependentIT
Managing External Bulk Resources
Demonstrates managing multiple external resources (non-Kubernetes) using bulk dependent resources. This pattern allows operators to manage a variable number of external resources based on primary resource specifications, handling creation, updates, and deletion of external resources at scale.
Package: io.javaoperatorsdk.operator.dependent.bulkdependent.external
ManagedBulkDependentIT
Bulk Dependent Resources with Managed Workflow
Demonstrates how to manage bulk dependent resources using the managed workflow approach. This test extends the base bulk dependent test to show how multiple instances of the same type of dependent resource can be created and managed together. The managed workflow handles the orchestration of creating, updating, and deleting multiple dependent resources based on the primary resource specification.
Package: io.javaoperatorsdk.operator.dependent.bulkdependent.managed
ReadOnlyBulkDependentIT
Read-Only Bulk Dependent Resources
Demonstrates how to use read-only bulk dependent resources to observe and react to multiple existing resources without managing them. This test shows how an operator can monitor a collection of resources created externally and update the custom resource status based on their state, without creating or modifying them.
Package: io.javaoperatorsdk.operator.dependent.bulkdependent.readonly
StandaloneBulkDependentIT
Standalone Bulk Dependent Resources
Demonstrates how to use standalone bulk dependent resources to manage multiple resources of the same type efficiently. This test shows how bulk operations can be performed on a collection of resources without individual reconciliation cycles, improving performance when managing many similar resources.
Package: io.javaoperatorsdk.operator.dependent.bulkdependent.standalone
CleanerForManagedDependentResourcesOnlyIT
Cleanup handlers for managed dependent resources
Shows how to implement cleanup logic for managed dependent resources using the Cleaner interface. The framework automatically adds finalizers and invokes the cleanup method when the primary resource is deleted, ensuring proper cleanup of dependent resources.
Package: io.javaoperatorsdk.operator.dependent.cleanermanageddependent
CreateOnlyIfNotExistingDependentWithSSAIT
Create-Only Dependent Resources with Server-Side Apply
Demonstrates how to configure a dependent resource that is only created if it doesn’t exist, using Server-Side Apply (SSA). This test shows that when a resource already exists, the dependent resource implementation will not modify it, preserving any external changes.
Package: io.javaoperatorsdk.operator.dependent.createonlyifnotexistsdependentwithssa
DependentAnnotationSecondaryMapperIT
Annotation-Based Secondary Resource Mapping for Dependents
Demonstrates using annotations instead of owner references to map secondary resources to primary resources in dependent resources. This approach is useful when owner references cannot be used (e.g., cross-namespace or cluster-scoped relationships), using special annotations to establish the relationship.
Package: io.javaoperatorsdk.operator.dependent.dependentannotationsecondarymapper
DependentCustomMappingAnnotationIT
Custom Annotation Keys for Resource Mapping
Tests custom annotation-based mapping for dependent resources using configurable annotation keys instead of the default ones. This allows developers to customize which annotations are used to establish relationships between primary and secondary resources, providing flexibility for different naming conventions or avoiding conflicts.
Package: io.javaoperatorsdk.operator.dependent.dependentcustommappingannotation
DependentDifferentNamespaceIT
Dependent Resources in Different Namespaces
Demonstrates how to manage dependent resources in a namespace different from the primary resource. This test shows how to configure dependent resources to be created in a specific namespace rather than inheriting the namespace from the primary resource. The test verifies full CRUD operations for a ConfigMap that lives in a different namespace than the custom resource that manages it.
Package: io.javaoperatorsdk.operator.dependent.dependentdifferentnamespace
DependentFilterIT
Filtering Reconciliation Triggers from Dependent Resources
Demonstrates how to filter events from dependent resources to prevent unnecessary reconciliation triggers. This test shows how to configure filters on dependent resources so that only specific changes trigger a reconciliation of the primary resource. The test verifies that updates to filtered fields in the dependent resource do not cause the reconciler to execute, improving efficiency and avoiding reconciliation loops.
Package: io.javaoperatorsdk.operator.dependent.dependentfilter
DependentOperationEventFilterIT
Event filtering for dependent resource operations
Demonstrates how to configure event filters on dependent resources to prevent reconciliation loops. When a dependent resource is created or updated by the controller, the filter prevents those events from triggering unnecessary reconciliations.
Package: io.javaoperatorsdk.operator.dependent.dependentoperationeventfiltering
DependentReInitializationIT
Reusing Dependent Resource Instances Across Tests
Demonstrates that dependent resource instances can be safely reused across multiple operator start/stop cycles. This is particularly useful in CDI-managed environments like Quarkus, where dependent resources are managed as beans and should be reusable across test executions.
Package: io.javaoperatorsdk.operator.dependent.dependentreinitialization
DependentResourceCrossRefIT
Dependent Resources with Cross-References
Tests dependent resources that reference each other, creating interdependencies between multiple secondary resources. The test verifies that resources with circular or cross-references can be safely created, managed, and deleted without causing issues, even under concurrent operations with multiple primary resources.
Package: io.javaoperatorsdk.operator.dependent.dependentresourcecrossref
DependentSSAMatchingIT
Server-Side Apply (SSA) with Dependent Resources
Demonstrates how to use Server-Side Apply (SSA) with dependent resources and field manager matching. This test shows how SSA allows multiple controllers to manage different fields of the same resource without conflicts. The test verifies that changes made by different field managers are properly isolated, and that the operator only updates its own fields when changes occur, preserving fields managed by other controllers.
Package: io.javaoperatorsdk.operator.dependent.dependentssa
DependentSSAMigrationIT
Migrating Dependent Resources from Legacy to SSA
Demonstrates migrating dependent resource management from legacy update methods to Server-Side Apply (SSA). Tests show bidirectional migration scenarios and field manager handling, including using the default fabric8 field manager to avoid creating duplicate managed field entries during migration.
Package: io.javaoperatorsdk.operator.dependent.dependentssa
ExternalStateDependentIT
External State Tracking in Dependent Resources
Demonstrates managing dependent resources with external state that needs to be tracked independently of Kubernetes resources. This pattern allows operators to maintain state information for external systems or resources, ensuring proper reconciliation even when the external state differs from the desired Kubernetes resource state.
Package: io.javaoperatorsdk.operator.dependent.externalstate
ExternalStateIT
Managing External Resources with Persistent State
Demonstrates how to manage external resources (outside of Kubernetes) while maintaining their state in Kubernetes resources. This test shows a pattern for reconciling external systems by storing external resource identifiers in a ConfigMap. The test verifies that external resources can be created, updated, and deleted in coordination with Kubernetes resources, with the ConfigMap serving as a state store for external resource IDs.
Package: io.javaoperatorsdk.operator.dependent.externalstate
ExternalStateBulkIT
Bulk External State Management with Persistent State
Demonstrates managing multiple external resources with persistent state tracking using bulk dependent resources. This combines external state management with bulk operations, allowing operators to track and reconcile a variable number of external resources with persistent state that survives operator restarts.
Package: io.javaoperatorsdk.operator.dependent.externalstate.externalstatebulkdependent
GenericKubernetesDependentManagedIT
Generic Kubernetes Dependent Resource (Managed)
Demonstrates how to use GenericKubernetesResource as a managed dependent resource. This test shows how to work with generic Kubernetes resources that don’t have a specific Java model class, allowing the operator to manage any Kubernetes resource type dynamically.
GenericKubernetesDependentStandaloneIT
Generic Kubernetes Resource as Standalone Dependent
Tests using GenericKubernetesResource as a standalone dependent resource. This approach allows operators to manage arbitrary Kubernetes resources without requiring specific Java classes for each resource type, providing flexibility for managing various resource types dynamically.
Package: io.javaoperatorsdk.operator.dependent.generickubernetesresource.generickubernetesdependentstandalone
KubernetesDependentGarbageCollectionIT
Kubernetes Native Garbage Collection for Dependent Resources
Demonstrates how to leverage Kubernetes native garbage collection for dependent resources using owner references. This test shows how dependent resources are automatically cleaned up by Kubernetes when the owner resource is deleted, and how to conditionally create or delete dependent resources based on the primary resource state. Owner references ensure that dependent resources don’t outlive their owners.
Package: io.javaoperatorsdk.operator.dependent.kubernetesdependentgarbagecollection
MultipleDependentResourceIT
Managing Multiple Dependent Resources
Demonstrates how to manage multiple dependent resources from a single reconciler. This test shows how a single custom resource can create, update, and delete multiple ConfigMaps (or other Kubernetes resources) as dependents. The test verifies that all dependent resources are created together, updated together when the primary resource changes, and properly cleaned up when the primary resource is deleted.
Package: io.javaoperatorsdk.operator.dependent.multipledependentresource
MultipleDependentResourceWithNoDiscriminatorIT
Multiple Dependents of Same Type Without Discriminator
Demonstrates managing multiple dependent resources of the same type (ConfigMaps) without using discriminators. The framework uses resource names to differentiate between them, simplifying configuration when distinct names are sufficient for identification.
Package: io.javaoperatorsdk.operator.dependent.multipledependentresourcewithsametype
MultipleDependentSameTypeMultiInformerIT
Multiple Managed Dependents of Same Type with Multi-Informer
Tests managing multiple dependent resources of the same type using separate informers for each. This approach allows for independent event handling and caching for resources of the same type, useful when different caching strategies or event filtering is needed for different instances.
Package: io.javaoperatorsdk.operator.dependent.multipledependentsametypemultiinformer
MultipleManagedDependentNoDiscriminatorIT
Multiple Managed Dependents of Same Type Without Discriminator
Demonstrates managing multiple managed dependent resources of the same type without explicit discriminators. The test verifies complete CRUD operations on multiple ConfigMaps, showing that resource names alone can differentiate between dependents when a discriminator is not needed.
Package: io.javaoperatorsdk.operator.dependent.multipledrsametypenodiscriminator
MultipleManagedDependentSameTypeIT
Managing Multiple Dependent Resources of the Same Type
Demonstrates how to manage multiple dependent resources of the same type from a single reconciler. This test shows how multiple ConfigMaps with the same type can be created, updated, and deleted as dependent resources of a custom resource, verifying proper CRUD operations and garbage collection.
Package: io.javaoperatorsdk.operator.dependent.multiplemanageddependentsametype
MultipleManagedExternalDependentSameTypeIT
Multiple Managed External Dependents of Same Type
Tests managing multiple external (non-Kubernetes) dependent resources of the same type. This demonstrates that operators can manage multiple instances of external resources simultaneously, handling their lifecycle including creation, updates, and deletion.
Package: io.javaoperatorsdk.operator.dependent.multiplemanagedexternaldependenttype
MultiOwnerDependentTriggeringIT
Dependent Resource Shared by Multiple Owners
Demonstrates a dependent resource (ConfigMap) that is managed by multiple primary resources simultaneously. Tests verify that updates from any owner trigger proper reconciliation, owner references are correctly maintained, and the shared resource properly aggregates data from all owners.
Package: io.javaoperatorsdk.operator.dependent.multipleupdateondependent
PrevAnnotationBlockReconcilerIT
Blocking Previous Annotation for Specific Resource Types
Tests the previous annotation blocklist feature, which prevents storing previous resource state annotations for specific resource types like Deployments. This optimization avoids unnecessary reconciliation loops for resources that have server-side mutations, improving performance and stability.
Package: io.javaoperatorsdk.operator.dependent.prevblocklist
DependentPrimaryIndexerIT
Primary Resource Indexer with Dependent Resources
Extends PrimaryIndexerIT to test primary resource indexing functionality with dependent resources. Demonstrates how custom indexes on primary resources can be used to efficiently query and access resources within dependent resource implementations, enabling performant lookups.
Package: io.javaoperatorsdk.operator.dependent.primaryindexer
PrimaryToSecondaryDependentIT
Primary to Secondary Dependent Resource
Demonstrates how to configure dependencies between dependent resources where one dependent resource (secondary) depends on another dependent resource (primary). This test shows how a Secret’s creation can be conditioned on the state of a ConfigMap, illustrating the use of reconcile preconditions and dependent resource chaining.
Package: io.javaoperatorsdk.operator.dependent.primarytosecondaydependent
OperatorRestartIT
Operator restart and state recovery
Tests that an operator can be stopped and restarted while maintaining correct behavior. After restart, the operator should resume processing existing resources without losing track of their state, demonstrating proper state recovery and persistence.
Package: io.javaoperatorsdk.operator.dependent.restart
ServiceStrictMatcherIT
Strict matching for Service resources
Shows how to use a strict matcher for Service dependent resources that correctly handles Service-specific fields. This prevents unnecessary updates when Kubernetes adds default values or modifies certain fields, avoiding reconciliation loops.
Package: io.javaoperatorsdk.operator.dependent.servicestrictmatcher
SpecialResourcesDependentIT
Handling special Kubernetes resources without spec
Demonstrates how to handle special built-in Kubernetes resources like ServiceAccount that don’t have a spec field. These resources require different handling approaches since their configuration is stored directly in the resource body rather than in a spec section.
Package: io.javaoperatorsdk.operator.dependent.specialresourcesdependent
SSAWithLegacyMatcherIT
Using Legacy Resource Matcher with SSA
Demonstrates using the legacy resource matcher with Server-Side Apply (SSA). The legacy matcher provides backward compatibility for matching logic while using SSA for updates, ensuring that resource comparisons work correctly even when migrating from traditional update methods to SSA.
Package: io.javaoperatorsdk.operator.dependent.ssalegacymatcher
StandaloneDependentResourceIT
Standalone Dependent Resources
Demonstrates how to use standalone dependent resources that are managed independently without explicit workflow configuration. This test shows how dependent resources can be created and managed programmatically, with the dependent resource handling CRUD operations on a Kubernetes Deployment. The test verifies both creation and update scenarios, including cache updates when the dependent resource state changes.
Package: io.javaoperatorsdk.operator.dependent.standalonedependent
StatefulSetDesiredSanitizerIT
Sanitizing StatefulSet desired state for SSA
Shows how to properly sanitize StatefulSet resources before using Server-Side Apply. StatefulSets have immutable fields and server-managed fields that need to be removed from the desired state to prevent conflicts and unnecessary updates.
Package: io.javaoperatorsdk.operator.dependent.statefulsetdesiredsanitizer
Workflows
ComplexWorkflowIT
Complex Workflow with Multiple Dependents
Demonstrates a complex workflow with multiple dependent resources (StatefulSets and Services) that have dependencies on each other. This test shows how to orchestrate the reconciliation of interconnected dependent resources in a specific order.
Package: io.javaoperatorsdk.operator.workflow.complexdependent
CRDPresentActivationConditionIT
Workflow Activation Based on CRD Presence
Tests workflow activation conditions that depend on the presence of specific Custom Resource Definitions (CRDs). Dependent resources are only created when their corresponding CRDs exist in the cluster, allowing operators to gracefully handle optional dependencies and multi-cluster scenarios.
Package: io.javaoperatorsdk.operator.workflow.crdpresentactivation
WorkflowInactiveDependentAccessIT
Workflow Functions on Vanilla Kubernetes Despite Inactive Resources
Verifies that workflows function correctly on vanilla Kubernetes even when they include resources that are not available on the platform (like OpenShift Routes). The operator successfully reconciles by skipping inactive dependents based on activation conditions, demonstrating platform-agnostic operator design.
Package: io.javaoperatorsdk.operator.workflow.getnonactivesecondary
ManagedDependentDeleteConditionIT
Managed Dependent Delete Condition
Demonstrates how to use delete conditions to control when dependent resources can be deleted. This test shows how the primary resource deletion can be blocked until dependent resources are properly cleaned up, ensuring graceful shutdown and preventing orphaned resources.
Package: io.javaoperatorsdk.operator.workflow.manageddependentdeletecondition
MultipleDependentWithActivationIT
Multiple Dependents with Activation Conditions
Demonstrates how to use activation conditions with multiple dependent resources. This test shows how different dependent resources can be dynamically enabled or disabled based on runtime conditions, allowing flexible workflow behavior that adapts to changing requirements.
Package: io.javaoperatorsdk.operator.workflow.multipledependentwithactivation
OrderedManagedDependentIT
Ordered Managed Dependent Resources
Demonstrates how to control the order of reconciliation for managed dependent resources. This test verifies that dependent resources are reconciled in a specific sequence, ensuring proper orchestration when dependencies have ordering requirements.
Package: io.javaoperatorsdk.operator.workflow.orderedmanageddependent
WorkflowActivationCleanupIT
Workflow Activation Cleanup
Demonstrates how workflow cleanup is handled when activation conditions are involved. This test verifies that resources are properly cleaned up on operator startup even when marked for deletion, ensuring no orphaned resources remain after restarts.
Package: io.javaoperatorsdk.operator.workflow.workflowactivationcleanup
WorkflowActivationConditionIT
Workflow Activation Condition
Demonstrates how to use activation conditions to conditionally enable or disable parts of a workflow. This test shows how the workflow can adapt to different environments (e.g., vanilla Kubernetes vs. OpenShift) by activating only the relevant dependent resources based on runtime conditions.
Package: io.javaoperatorsdk.operator.workflow.workflowactivationcondition
WorkflowAllFeatureIT
Comprehensive workflow with reconcile and delete conditions
Demonstrates a complete workflow implementation including reconcile conditions, delete conditions, and ready conditions. Shows how to control when dependent resources are created or deleted based on conditions, and how to coordinate dependencies that must wait for others to be ready.
Package: io.javaoperatorsdk.operator.workflow.workflowallfeature
WorkflowExplicitCleanupIT
Explicit Workflow Cleanup Invocation
Tests explicit workflow cleanup invocation, demonstrating that workflow cleanup is called even when using explicit workflow invocation mode. This ensures that dependent resources are properly cleaned up during deletion regardless of how the workflow is invoked, maintaining consistent cleanup behavior.
Package: io.javaoperatorsdk.operator.workflow.workflowexplicitcleanup
WorkflowExplicitInvocationIT
Workflow Explicit Invocation
Demonstrates how to explicitly control when a workflow is invoked rather than having it run automatically on every reconciliation. This test shows how to programmatically trigger workflow execution and how cleanup is still performed even with explicit invocation.
Package: io.javaoperatorsdk.operator.workflow.workflowexplicitinvocation
WorkflowMultipleActivationIT
Dynamic Workflow Activation and Deactivation
Tests dynamic activation and deactivation of workflow dependents based on changing conditions. Demonstrates that dependents can be conditionally activated or deactivated during the resource lifecycle, with proper cleanup and recreation, and verifies that inactive dependents don’t trigger reconciliation or maintain informers.
Package: io.javaoperatorsdk.operator.workflow.workflowmultipleactivation
WorkflowSilentExceptionHandlingIT
Silent Workflow Exception Handling in Reconciler
Demonstrates handling workflow exceptions silently within the reconciler rather than propagating them. Tests verify that exceptions from dependent resources during both reconciliation and cleanup are captured in the result object, allowing custom error handling logic without failing the entire reconciliation.
Package: io.javaoperatorsdk.operator.workflow.workflowsilentexceptionhandling
4 - FAQ
Events and Reconciliation
How can I access the events that triggered reconciliation?
In v1.* versions, events were exposed to Reconciler (then called ResourceController). This included custom resource events (Create, Update) and events from Event Sources. After extensive discussions with golang controller-runtime developers, we decided to remove event access.
Why this change was made:
- Events can be lost in distributed systems
- Best practice is to reconcile all resources on every execution
- Aligns with Kubernetes level-based reconciliation approach
Recommendation: Always reconcile all resources instead of relying on specific events.
Can I reschedule a reconciliation with a specific delay?
Yes, you can reschedule reconciliation using UpdateControl and DeleteControl.
With status update:
@Override
public UpdateControl<MyCustomResource> reconcile(
EventSourceTestCustomResource resource, Context context) {
// ... reconciliation logic
return UpdateControl.patchStatus(resource).rescheduleAfter(10, TimeUnit.SECONDS);
}
Without an update:
@Override
public UpdateControl<MyCustomResource> reconcile(
EventSourceTestCustomResource resource, Context context) {
// ... reconciliation logic
return UpdateControl.<MyCustomResource>noUpdate().rescheduleAfter(10, TimeUnit.SECONDS);
}
Note: Consider using EventSources for smarter reconciliation triggering instead of time-based scheduling.
How can I make status updates trigger reconciliation?
By default, the framework filters out events that don’t increase the generation field of the primary resource’s metadata. Since generation typically only increases when the .spec field changes, status-only changes won’t trigger reconciliation.
To change this behavior, set generationAwareEventProcessing to false:
@ControllerConfiguration(generationAwareEventProcessing = false)
static class TestCustomReconciler implements Reconciler<TestCustomResource> {
@Override
public UpdateControl<TestCustomResource> reconcile(
TestCustomResource resource, Context<TestCustomResource> context) {
// reconciliation logic
}
}
For secondary resources, every change should trigger reconciliation by default, except when you add explicit filters or use dependent resource implementations that filter out self-triggered changes. See related docs.
Permissions and Access Control
How can I run an operator without cluster-scope rights?
By default, JOSDK requires cluster-scope access to custom resources. Without these rights, you’ll see startup errors like:
io.fabric8.kubernetes.client.KubernetesClientException: Failure executing: GET at: https://kubernetes.local.svc/apis/mygroup/v1alpha1/mycr. Message: Forbidden! Configured service account doesn't have access. Service account may have been revoked. mycrs.mygroup is forbidden: User "system:serviceaccount:ns:sa" cannot list resource "mycrs" in API group "mygroup" at the cluster scope.
Solution 1: Restrict to specific namespaces
Override watched namespaces using Reconciler-level configuration:
Operator operator;
Reconciler reconciler;
// ...
operator.register(reconciler, configOverrider ->
configOverrider.settingNamespace("mynamespace"));
Note: You can also configure watched namespaces using the @ControllerConfiguration annotation.
Solution 2: Disable CRD validation
If you can’t list CRDs at startup (required when checkingCRDAndValidateLocalModel is true), disable it using Operator-level configuration:
Operator operator = new Operator(override -> override.checkingCRDAndValidateLocalModel(false));
State Management
Where should I store generated IDs for external resources?
When managing external (non-Kubernetes) resources, they often have generated IDs that aren’t simply addressable based on your custom resource spec. You need to store these IDs for subsequent reconciliations.
Storage Options:
- Separate resource (usually ConfigMap, Secret, or dedicated CustomResource)
- Custom resource status field
Important considerations:
Both approaches require guaranteeing resources are cached for the next reconciliation. If you patch status at the end of reconciliation (UpdateControl.patchStatus(...)), the fresh resource isn’t guaranteed to be available during the next reconciliation. Controllers typically cache updated status in memory to ensure availability.
Modern solution: From version 5.1, use this utility to ensure updated status is available for the next reconciliation.
Dependent Resources: This feature supports the first approach natively.
Advanced Use Cases
How can I skip the reconciliation of a dependent resource?
Skipping workflow reconciliation altogether is possible with the explicit invocation feature since v5. You can read more about this in v5 release notes.
However, what if you want to avoid reconciling a single dependent resource based on some state? First, remember that the dependent resource won’t be modified if the desired state and actual state match. Moreover, it’s generally good practice to reconcile all your resources, with JOSDK taking care of only processing resources whose state doesn’t match the desired one.
However, in some corner cases (for example, if it’s expensive to compute the desired state or compare it to the actual state), it’s sometimes useful to skip the reconciliation of some resources but not all, if it’s known that they don’t need processing based on the status of the custom resource.
A common mistake is to use ReconcilePrecondition. If the condition doesn’t hold, it will delete the resources. This is by design (although the name might be misleading), but not what we want in this case.
The correct approach is to override the matcher in the dependent resource:
public Result<R> match(R actualResource, R desired, P primary, Context<P> context) {
if (alreadyIsCertainState(primary.getStatus())) {
return true;
} else {
return super.match(actual, desired, primary, context);
}
}
This ensures the dependent resource isn’t updated if the primary resource is in a certain state.
Troubleshooting
How to fix SSL certificate issues with Rancher Desktop and k3d/k3s
This is a common issue when using k3d and the fabric8 client tries to connect to the cluster:
Caused by: javax.net.ssl.SSLHandshakeException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at java.base/sun.security.ssl.Alert.createSSLException(Alert.java:131)
at java.base/sun.security.ssl.TransportContext.fatal(TransportContext.java:352)
at java.base/sun.security.ssl.TransportContext.fatal(TransportContext.java:295)
Cause: The fabric8 kubernetes client doesn’t handle elliptical curve encryption by default.
Solution: Add the following dependency to your classpath:
<dependency>
<groupId>org.bouncycastle</groupId>
<artifactId>bcpkix-jdk15on</artifactId>
</dependency>
5 - Glossary
Primary Resource - The resource representing the desired state that the controller works to achieve. While often a Custom Resource, it can also be a native Kubernetes resource (Deployment, ConfigMap, etc.).
Secondary Resource - Any resource the controller needs to manage to reach the desired state represented by the primary resource. These can be created, updated, deleted, or simply read depending on the use case. For example, the
Deploymentcontroller managesReplicaSetinstances to realize the state represented by theDeployment. Here,Deploymentis the primary resource whileReplicaSetis a secondary resource.Dependent Resource - A JOSDK feature that makes managing secondary resources easier. A dependent resource represents a secondary resource with associated reconciliation logic.
Low-level API - SDK APIs that don’t use features beyond the core
Reconcilerinterface (such as Dependent Resources or Workflows). See the WebPage sample. The same logic is also implemented using Dependent Resource and Workflows.
6 - Contributing
Thank you for considering contributing to the Java Operator SDK project! We’re building a vibrant community and need help from people like you to make it happen.
Code of Conduct
We’re committed to making this a welcoming, inclusive project. We do not tolerate discrimination, aggressive or insulting behavior.
This project and all participants are bound by our Code of Conduct. By participating, you’re expected to uphold this code. Please report unacceptable behavior to any project admin.
Reporting Bugs
Found a bug? Please open an issue! Include all details needed to recreate the problem:
- Operator SDK version being used
- Exact platform and version you’re running on
- Steps to reproduce the bug
- Reproducer code (very helpful for quick diagnosis and fixes)
Contributing Features and Documentation
Looking for something to work on? Check the issue tracker, especially items labeled good first issue. Please comment on the issue when you start work to avoid duplicated effort.
Feature Ideas
Have a feature idea? Open an issue labeled “enhancement” even if you can’t work on it immediately. We’ll discuss it as a community and see what’s possible.
Important: Some features may not align with project goals. Please discuss new features before starting work to avoid wasted effort. We commit to listening to all proposals and working something out when possible.
Development Process
Once you have approval to work on a feature:
- Communicate progress via issue updates or our Discord channel
- Ask for feedback and pointers as needed
- Open a Pull Request when ready
Pull Request Process
Commit Messages
Format commit messages following conventional commit format.
Testing and Review
- GitHub Actions will run the test suite on your PR
- All code must pass tests
- New code must include new tests
- All PRs require review and sign-off from another developer
- Expect requests for changes - this is normal and part of the process
- PRs must comply with Java Google code style
Licensing
All Operator SDK code is released under the Apache 2.0 licence.
Development Environment Setup
Code Style
SDK modules and samples follow Java Google code style. Code gets formatted automatically on every compile, but to avoid PR rejections due to style issues, set up your IDE:
IntelliJ IDEA: Install the google-java-format plugin
Eclipse: Follow these instructions
Acknowledgments
These guidelines were inspired by Atom, PurpleBooth’s advice, and the Contributor Covenant.
7 - Migrations
7.1 - Migrating from v1 to v2
Version 2 of the framework introduces improvements, features and breaking changes for the APIs both
internal and user facing ones. The migration should be however trivial in most of the cases. For
detailed overview of all major issues until the release of
v2.0.0 see milestone on GitHub
. For a summary and reasoning behind some naming changes
see this issue
User Facing API Changes
The following items are renamed and slightly changed:
ResourceControllerinterface is renamed toReconciler. In addition, methods:createOrUpdateResourcerenamed toreconciledeleteResourcerenamed tocleanup
- Events are removed from
the
ContextofReconcilermethods . The rationale behind this, is that there is a consensus now on the pattern that the events should not be used to implement a reconciliation logic. - The
initmethod is extracted fromResourceController/Reconcilerto a separate interface called EventSourceInitializer thatReconcilershould implement in order to register event sources. The method has been renamed toprepareEventSourcesand should now return a list ofEventSourceimplementations that theControllerwill automatically register. See also sample for usage. EventSourceManageris now an internal class that users shouldn’t need to interact with.@Controllerannotation renamed to@ControllerConfiguration- The metrics use
reconcile,cleanupandresourcelabels instead ofcreateOrUpdate,deleteandcr, respectively to match the new logic.
Event Sources
- Addressing resources within event sources (and in the framework internally) is now changed
from
.metadata.uidto a pair of.metadata.nameand optional.metadata.namespaceof resource. Represented byResourceID.
The Event
API is simplified. Now if an event source produces an event it needs to just produce an instance of
this class.
EventSourceis refactored, but the changes are trivial.
7.2 - Migrating from v2 to v3
Version 3 introduces some breaking changes to APIs, however the migration to these changes should be trivial.
Reconciler
Reconcilercan throw checked exception (not just runtime exception), and that also can be handled byErrorStatusHandler.cleanupmethod is extracted from theReconcilerinterface to a separateCleanerinterface. Finalizers only makes sense that theCleanupis implemented, from now finalizer is only added if theReconcilerimplements this interface (or has managed dependent resources implementingDeleterinterface, see dependent resource docs).Contextobject ofReconcilernow takes the Primary resource as parametrized type:Context<MyCustomResource>.ErrorStatusHandlerresult changed, it functionally has been extended to now prevent Exception to be retried and handles checked exceptions as mentioned above.
Event Sources
- Event Sources are now registered with a name. But utility method is available to make it easy to migrate to a default name.
- InformerEventSource
constructor changed to reflect additional functionality in a non backwards compatible way. All the configuration
options from the constructor where moved to
InformerConfiguration. See sample usage inWebPageReconciler. PrimaryResourcesRetrieverwas renamed toSecondaryToPrimaryMapperAssociatedSecondaryResourceIdentifierwas renamed toPrimaryToSecondaryMappergetAssociatedResourceis now renamed to getgetSecondaryResourcein multiple places
7.3 - Migrating from v3 to v3.1
ReconciliationMaxInterval Annotation has been renamed to MaxReconciliationInterval
Associated methods on both the ControllerConfiguration class and annotation have also been
renamed accordingly.
Workflows Impact on Managed Dependent Resources Behavior
Version 3.1 comes with a workflow engine that replaces the previous behavior of managed dependent resources. See Workflows documentation for further details. The primary impact after upgrade is a change of the order in which managed dependent resources are reconciled. They are now reconciled in parallel with optional ordering defined using the ‘depends_on’ relation to define order between resources if needed. In v3, managed dependent resources were implicitly reconciled in the order they were defined in.
Garbage Collected Kubernetes Dependent Resources
In version 3 all Kubernetes Dependent Resource
implementing Deleter
interface were meant to be also using owner references (thus garbage collected by Kubernetes).
In 3.1 there is a
dedicated GarbageCollected
interface to distinguish between Kubernetes resources meant to be garbage collected or explicitly
deleted. Please refer also to the GarbageCollected javadoc for more details on how this
impacts how owner references are managed.
The supporting classes were also updated. Instead
of CRUKubernetesDependentResource
there are two:
CRUDKubernetesDependentResourcethat isGarbageCollectedCRUDNoGCKubernetesDependentResourcewhat isDeleterbut notGarbageCollected
Use the one according to your use case. We anticipate that most people would want to use
CRUDKubernetesDependentResource whenever they have to work with Kubernetes dependent resources.
7.4 - Migrating from v4.2 to v4.3
Condition API Change
In Workflows the target of the condition was the managed resource itself, not the target dependent resource. This changed, now the API contains the dependent resource.
New API:
public interface Condition<R, P extends HasMetadata> {
boolean isMet(DependentResource<R, P> dependentResource, P primary, Context<P> context);
}
Former API:
public interface Condition<R, P extends HasMetadata> {
boolean isMet(P primary, R secondary, Context<P> context);
}
Migration is trivial. Since the secondary resource can be accessed from the dependent resource. So to access the
secondary
resource just use dependentResource.getSecondaryResource(primary,context).
HTTP client choice
It is now possible to change the HTTP client used by the Fabric8 client to communicate with the Kubernetes API server.
By default, the SDK uses the historical default HTTP client which relies on Okhttp and there shouldn’t be anything
needed to keep using this implementation. The tomcat-operator sample has been migrated to use the Vert.X based
implementation. You can see how to change the client by looking at
that sample POM file:
- You need to exclude the default implementation (in this case okhttp) from the
operator-frameworkdependency - You need to add the appropriate implementation dependency,
kubernetes-httpclient-vertxin this case, HTTP client implementations provided as part of the Fabric8 client all following thekubernetes-httpclient-<implementation name>pattern for their artifact identifier.
7.5 - Migrating from v4.3 to v4.4
API changes
ConfigurationService
We have simplified how to deal with the Kubernetes client. Previous versions provided direct
access to underlying aspects of the client’s configuration or serialization mechanism. However,
the link between these aspects wasn’t as explicit as it should have been. Moreover, the Fabric8
client framework has also revised their serialization architecture in the 6.7 version (see this
fabric8 pull request for a discussion of
that change), moving from statically configured serialization to a per-client configuration
(though it’s still possible to share serialization mechanism between client instances). As a
consequence, we made the following changes to the ConfigurationService API:
- Replaced
getClientConfigurationandgetObjectMappermethods by a newgetKubernetesClientmethod: instead of providing the configuration and mapper, you now provide a client instance configured according to your needs and the SDK will extract the needed information from it
If you had previously configured a custom configuration or ObjectMapper, it is now recommended
that you do so when creating your client instance, as follows, usually using
ConfigurationServiceOverrider.withKubernetesClient:
class Example {
public static void main(String[] args) {
Config config; // your configuration
ObjectMapper mapper; // your mapper
final var operator = new Operator(overrider -> overrider.withKubernetesClient(
new KubernetesClientBuilder()
.withConfig(config)
.withKubernetesSerialization(new KubernetesSerialization(mapper, true))
.build()
));
}
}
Consequently, it is now recommended to get the client instance from the ConfigurationService.
Operator
It is now recommended to configure your Operator instance by using a
ConfigurationServiceOverrider when creating it. This allows you to change the default
configuration values as needed. In particular, instead of passing a Kubernetes client instance
explicitly to the Operator constructor, it is now recommended to provide that value using
ConfigurationServiceOverrider.withKubernetesClient as shown above.
Using Server-Side Apply in Dependent Resources
From this version by
default Dependent Resources use
Server Side Apply (SSA) to
create and
update Kubernetes resources. A
new default matching
algorithm is provided for KubernetesDependentResource that is based on managedFields of SSA. For
details
see SSABasedGenericKubernetesResourceMatcher
Since those features are hard to completely test, we provided feature flags to revert to the legacy behavior if needed, see in ConfigurationService
Note that it is possible to override the related methods/behavior on class level when extending
the KubernetesDependentResource.
The SSA based create/update can be combined with the legacy matcher, simply override the match method
and use the GenericKubernetesResourceMatcher
directly. See related sample.
Migration from plain Update/Create to SSA Based Patch
Migration to SSA might not be trivial based on the uses cases and the type of managed resources. In general this is not a solved problem is Kubernetes. The Java Operator SDK Team tries to follow the related issues, but in terms of implementation this is not something that the framework explicitly supports. Thus, no code is added that tries to mitigate related issues. Users should thoroughly test the migration, and even consider not to migrate in some cases (see feature flags above).
See some related issues in kubernetes or here. Please create related issue in JOSDK if any.
7.6 - Migrating from v4.4 to v4.5
Version 4.5 introduces improvements related to event handling for Dependent Resources, more precisely the caching and event handling features. As a result the Kubernetes resources managed using KubernetesDependentResource or its subclasses, will add an annotation recording the resource’s version whenever JOSDK updates or creates such resources. This can be turned off using a feature flag if causes some issues in your use case.
Using this feature, JOSDK now tracks versions of cached resources. It also uses, by default, that information to prevent
unneeded reconciliations that could occur when, depending on the timing of operations, an outdated resource would happen
to be in the cache. This relies on the fact that versions (as recorded by the metadata.resourceVersion field) are
currently implemented as monotonically increasing integers (though they should be considered as opaque and their
interpretation discouraged). Note that, while this helps preventing unneeded reconciliations, things would eventually
reach consistency even in the absence of this feature. Also, if this interpreting of the resource versions causes
issues, you can turn the feature off using the
following feature flag.
7.8 - Migrating from v5.1 to v5.2
Version 5.2 brings some breaking changes to certain components. This document provides a migration guide for these changes. For all the new features, see the release notes.
Custom ID types across multiple components using ResourceIDMapper and ResourceIDProvider
Working with the id of a resource is needed across various components in the framework.
Until this version, the components provided by the framework assumed that you could easily
convert the id of a resource into a String representation. For example,
BulkDependentResources
worked with a Map<String,R> of resources, where the id was always of type String.
Mainly because of the need to manage external dependent resources more elegantly,
we introduced a cross-cutting concept: ResourceIDMapper,
which gets the ID of a resource. This is used across various components, see:
ExternalResourceCachingEventSourceExternalBulkDependentResourceAbstractExternalDependentResourceand its subclasses.
We also added ResourceIDProvider,
which you can implement in your Pojo representing a resource.
The easiest way to migrate to this new approach is to implement this interface for your (external) resource
and set the ID type generics for the components above. The default implementation of the ResourceIDMapper
works with ResourceIDProvider (see related implementation).
If you cannot implement ResourceIDProvider because, for example, the class that represents the external resource is generated and final,
you can always set a custom ResourceIDMapper on the components above.
See also: