Features
Features
The Java Operator SDK (JOSDK) is a high level framework and related tooling aimed at facilitating the implementation of Kubernetes operators. The features are by default following the best practices in an opinionated way. However, feature flags and other configuration options are provided to fine tune or turn off these features.
Reconciliation Execution in a Nutshell
Reconciliation execution is always triggered by an event. Events typically come from a primary resource, most of the time a custom resource, triggered by changes made to that resource on the server (e.g. a resource is created, updated or deleted). Reconciler implementations are associated with a given resource type and listens for such events from the Kubernetes API server so that they can appropriately react to them. It is, however, possible for secondary sources to trigger the reconciliation process. This usually occurs via the event source mechanism.
When an event is received reconciliation is executed, unless a reconciliation is already underway for this particular resource. In other words, the framework guarantees that no concurrent reconciliation happens for any given resource.
Once the reconciliation is done, the framework checks if:
- an exception was thrown during execution and if yes schedules a retry.
- new events were received during the controller execution, if yes schedule a new reconciliation.
- the reconcilier instructed the SDK to re-schedule a reconciliation at a later date, if yes schedules a timer event with the specified delay.
- none of the above, the reconciliation is finished.
In summary, the core of the SDK is implemented as an eventing system, where events trigger reconciliation requests.
Implementing a Reconciler and/or Cleaner
The lifecycle of a Kubernetes resource can be clearly separated into two phases from the perspective of an operator depending on whether a resource is created or updated, or on the other hand if it is marked for deletion.
This separation-related logic is automatically handled by the framework. The framework will always
call the reconcile method, unless the custom resource is
marked from deletion
. On the other, if the resource is marked from deletion and if the Reconciler implements the
Cleaner interface, only the cleanup method will be called. Implementing the Cleaner
interface allows developers to let the SDK know that they are interested in cleaning related
state (e.g. out-of-cluster resources). The SDK will therefore automatically add a finalizer
associated with your Reconciler so that the Kubernetes server doesn’t delete your resources
before your Reconciler gets a chance to clean things up.
See Finalizer support for more details.
Using UpdateControl and DeleteControl
These two classes are used to control the outcome or the desired behaviour after the reconciliation.
The UpdateControl
can instruct the framework to update the status sub-resource of the resource
and/or re-schedule a reconciliation with a desired time delay:
@Override
public UpdateControl<MyCustomResource> reconcile(
EventSourceTestCustomResource resource, Context context) {
// omitted code
return UpdateControl.patchStatus(resource).rescheduleAfter(10, TimeUnit.SECONDS);
}
without an update:
@Override
public UpdateControl<MyCustomResource> reconcile(
EventSourceTestCustomResource resource, Context context) {
// omitted code
return UpdateControl.<MyCustomResource>noUpdate().rescheduleAfter(10, TimeUnit.SECONDS);
}
Note, though, that using EventSources should be preferred to rescheduling since the
reconciliation will then be triggered only when needed instead than on a timely basis.
Those are the typical use cases of resource updates, however in some cases there it can happen that the controller wants to update the resource itself (for example to add annotations) or not perform any updates, which is also supported.
It is also possible to update both the status and the resource with the patchResourceAndStatus method. In this case,
the resource is updated first followed by the status, using two separate requests to the Kubernetes API.
From v5 UpdateControl only supports patching the resources, by default
using Server Side Apply (SSA).
It is important to understand how SSA works in Kubernetes. Mainly, resources applied using SSA
should contain only the fields identifying the resource and those the user is interested in (a ‘fully specified intent’
in Kubernetes parlance), thus usually using a resource created from scratch, see
sample.
To contrast, see the same sample, this time without SSA.
Non-SSA based patch is still supported.
You can control whether or not to use SSA
using ConfigurationServcice.useSSAToPatchPrimaryResource()
and the related ConfigurationServiceOverrider.withUseSSAToPatchPrimaryResource method.
Related integration test can be
found here.
Handling resources directly using the client, instead of delegating these updates operations to JOSDK by returning
an UpdateControl at the end of your reconciliation, should work appropriately. However, we do recommend to
use UpdateControl instead since JOSDK makes sure that the operations are handled properly, since there are subtleties
to be aware of. For example, if you are using a finalizer, JOSDK makes sure to include it in your fully specified intent
so that it is not unintentionally removed from the resource (which would happen if you omit it, since your controller is
the designated manager for that field and Kubernetes interprets the finalizer being gone from the specified intent as a
request for removal).
DeleteControl
typically instructs the framework to remove the finalizer after the dependent
resource are cleaned up in cleanup implementation.
public DeleteControl cleanup(MyCustomResource customResource,Context context){
// omitted code
return DeleteControl.defaultDelete();
}
However, it is possible to instruct the SDK to not remove the finalizer, this allows to clean up
the resources in a more asynchronous way, mostly for cases when there is a long waiting period
after a delete operation is initiated. Note that in this case you might want to either schedule
a timed event to make sure cleanup is executed again or use event sources to get notified
about the state changes of the deleted resource.
Finalizer Support
Kubernetes finalizers
make sure that your Reconciler gets a chance to act before a resource is actually deleted
after it’s been marked for deletion. Without finalizers, the resource would be deleted directly
by the Kubernetes server.
Depending on your use case, you might or might not need to use finalizers. In particular, if
your operator doesn’t need to clean any state that would not be automatically managed by the
Kubernetes cluster (e.g. external resources), you might not need to use finalizers. You should
use the
Kubernetes garbage collection
mechanism as much as possible by setting owner references for your secondary resources so that
the cluster can automatically deleted them for you whenever the associated primary resource is
deleted. Note that setting owner references is the responsibility of the Reconciler
implementation, though dependent resources
make that process easier.
If you do need to clean such state, you need to use finalizers so that their presence will prevent the Kubernetes server from deleting the resource before your operator is ready to allow it. This allows for clean up to still occur even if your operator was down when the resources was “deleted” by a user.
JOSDK makes cleaning resources in this fashion easier by taking care of managing finalizers
automatically for you when needed. The only thing you need to do is let the SDK know that your
operator is interested in cleaning state associated with your primary resources by having it
implement
the Cleaner<P>
interface. If your Reconciler doesn’t implement the Cleaner interface, the SDK will consider
that you don’t need to perform any clean-up when resources are deleted and will therefore not
activate finalizer support. In other words, finalizer support is added only if your Reconciler
implements the Cleaner interface.
Finalizers are automatically added by the framework as the first step, thus after a resource is created, but before the first reconciliation. The finalizer is added via a separate Kubernetes API call. As a result of this update, the finalizer will then be present on the resource. The reconciliation can then proceed as normal.
The finalizer that is automatically added will be also removed after the cleanup is executed on
the reconciler. This behavior is customizable as explained
above when we addressed the use of
DeleteControl.
You can specify the name of the finalizer to use for your Reconciler using the
@ControllerConfiguration
annotation. If you do not specify a finalizer name, one will be automatically generated for you.
From v5 by default finalizer is added using Served Side Apply. See also UpdateControl in docs.
Generation Awareness and Event Filtering
A best practice when an operator starts up is to reconcile all the associated resources because changes might have occurred to the resources while the operator was not running.
When this first reconciliation is done successfully, the next reconciliation is triggered if either
dependent resources are changed or the primary resource .spec field is changed. If other fields
like .metadata are changed on the primary resource, the reconciliation could be skipped. This
behavior is supported out of the box and reconciliation is by default not triggered if
changes to the primary resource do not increase the .metadata.generation field.
Note that changes to .metada.generation are automatically handled by Kubernetes.
To turn off this feature, set generationAwareEventProcessing to false for the Reconciler.
Support for Well Known (non-custom) Kubernetes Resources
A Controller can be registered for a non-custom resource, so well known Kubernetes resources like (
Ingress, Deployment,…).
See the integration test for reconciling deployments.
public class DeploymentReconciler
implements Reconciler<Deployment>, TestExecutionInfoProvider {
@Override
public UpdateControl<Deployment> reconcile(
Deployment resource, Context context) {
// omitted code
}
}
Max Interval Between Reconciliations
When informers / event sources are properly set up, and the Reconciler implementation is
correct, no additional reconciliation triggers should be needed. However, it’s
a common practice
to have a failsafe periodic trigger in place, just to make sure resources are nevertheless
reconciled after a certain amount of time. This functionality is in place by default, with a
rather high time interval (currently 10 hours) after which a reconciliation will be
automatically triggered even in the absence of other events. See how to override this using the
standard annotation:
@ControllerConfiguration(maxReconciliationInterval = @MaxReconciliationInterval(
interval = 50,
timeUnit = TimeUnit.MILLISECONDS))
public class MyReconciler implements Reconciler<HasMetadata> {}
The event is not propagated at a fixed rate, rather it’s scheduled after each reconciliation. So the next reconciliation will occur at most within the specified interval after the last reconciliation.
This feature can be turned off by setting maxReconciliationInterval
to Constants.NO_MAX_RECONCILIATION_INTERVAL
or any non-positive number.
The automatic retries are not affected by this feature so a reconciliation will be re-triggered on error, according to the specified retry policy, regardless of this maximum interval setting.
Automatic Retries on Error
JOSDK will schedule an automatic retry of the reconciliation whenever an exception is thrown by
your Reconciler. The retry is behavior is configurable but a default implementation is provided
covering most of the typical use-cases, see
GenericRetry
.
GenericRetry.defaultLimitedExponentialRetry()
.setInitialInterval(5000)
.setIntervalMultiplier(1.5D)
.setMaxAttempts(5);
You can also configure the default retry behavior using the @GradualRetry annotation.
It is possible to provide a custom implementation using the retry field of the
@ControllerConfiguration annotation and specifying the class of your custom implementation.
Note that this class will need to provide an accessible no-arg constructor for automated
instantiation. Additionally, your implementation can be automatically configured from an
annotation that you can provide by having your Retry implementation implement the
AnnotationConfigurable interface, parameterized with your annotation type. See the
GenericRetry implementation for more details.
Information about the current retry state is accessible from
the Context
object. Of note, particularly interesting is the isLastAttempt method, which could allow your
Reconciler to implement a different behavior based on this status, by setting an error message
in your resource’ status, for example, when attempting a last retry.
Note, though, that reaching the retry limit won’t prevent new events to be processed. New reconciliations will happen for new events as usual. However, if an error also occurs that would normally trigger a retry, the SDK won’t schedule one at this point since the retry limit is already reached.
A successful execution resets the retry state.
Setting Error Status After Last Retry Attempt
In order to facilitate error reporting, Reconciler can implement the
ErrorStatusHandler
interface:
public interface ErrorStatusHandler<P extends HasMetadata> {
ErrorStatusUpdateControl<P> updateErrorStatus(P resource, Context<P> context, Exception e);
}
The updateErrorStatus method is called in case an exception is thrown from the Reconciler. It is
also called even if no retry policy is configured, just after the reconciler execution.
RetryInfo.getAttemptCount() is zero after the first reconciliation attempt, since it is not a
result of a retry (regardless of whether a retry policy is configured or not).
ErrorStatusUpdateControl is used to tell the SDK what to do and how to perform the status
update on the primary resource, always performed as a status sub-resource request. Note that
this update request will also produce an event, and will result in a reconciliation if the
controller is not generation aware.
This feature is only available for the reconcile method of the Reconciler interface, since
there should not be updates to resource that have been marked for deletion.
Retry can be skipped in cases of unrecoverable errors:
ErrorStatusUpdateControl.patchStatus(customResource).withNoRetry();
Correctness and Automatic Retries
While it is possible to deactivate automatic retries, this is not desirable, unless for very
specific reasons. Errors naturally occur, whether it be transient network errors or conflicts
when a given resource is handled by a Reconciler but is modified at the same time by a user in
a different process. Automatic retries handle these cases nicely and will usually result in a
successful reconciliation.
Retry and Rescheduling and Event Handling Common Behavior
Retry, reschedule and standard event processing form a relatively complex system, each of these functionalities interacting with the others. In the following, we describe the interplay of these features:
A successful execution resets a retry and the rescheduled executions which were present before the reconciliation. However, a new rescheduling can be instructed from the reconciliation outcome (
UpdateControlorDeleteControl).For example, if a reconciliation had previously been re-scheduled after some amount of time, but an event triggered the reconciliation (or cleanup) in the mean time, the scheduled execution would be automatically cancelled, i.e. re-scheduling a reconciliation does not guarantee that one will occur exactly at that time, it simply guarantees that one reconciliation will occur at that time at the latest, triggering one if no event from the cluster triggered one. Of course, it’s always possible to re-schedule a new reconciliation at the end of that “automatic” reconciliation.
Similarly, if a retry was scheduled, any event from the cluster triggering a successful execution in the mean time would cancel the scheduled retry (because there’s now no point in retrying something that already succeeded)
In case an exception happened, a retry is initiated. However, if an event is received meanwhile, it will be reconciled instantly, and this execution won’t count as a retry attempt.
If the retry limit is reached (so no more automatic retry would happen), but a new event received, the reconciliation will still happen, but won’t reset the retry, and will still be marked as the last attempt in the retry info. The point (1) still holds, but in case of an error, no retry will happen.
The thing to keep in mind when it comes to retrying or rescheduling is that JOSDK tries to avoid unnecessary work. When you reschedule an operation, you instruct JOSDK to perform that operation at the latest by the end of the rescheduling delay. If something occurred on the cluster that triggers that particular operation (reconciliation or cleanup), then JOSDK considers that there’s no point in attempting that operation again at the end of the specified delay since there is now no point to do so anymore. The same idea also applies to retries.
Rate Limiting
It is possible to rate limit reconciliation on a per-resource basis. The rate limit also takes precedence over retry/re-schedule configurations: for example, even if a retry was scheduled for the next second but this request would make the resource go over its rate limit, the next reconciliation will be postponed according to the rate limiting rules. Note that the reconciliation is never cancelled, it will just be executed as early as possible based on rate limitations.
Rate limiting is by default turned off, since correct configuration depends on the reconciler
implementation, in particular, on how long a typical reconciliation takes.
(The parallelism of reconciliation itself can be
limited ConfigurationService
by configuring the ExecutorService appropriately.)
A default rate limiter implementation is provided, see:
PeriodRateLimiter
.
Users can override it by implementing their own
RateLimiter
and specifying this custom implementation using the rateLimiter field of the
@ControllerConfiguration annotation. Similarly to the Retry implementations,
RateLimiter implementations must provide an accessible, no-arg constructor for instantiation
purposes and can further be automatically configured from your own, provided annotation provided
your RateLimiter implementation also implements the AnnotationConfigurable interface,
parameterized by your custom annotation type.
To configure the default rate limiter use the @RateLimited annotation on your
Reconciler class. The following configuration limits each resource to reconcile at most twice
within a 3 second interval:
@RateLimited(maxReconciliations = 2, within = 3, unit = TimeUnit.SECONDS)
@ControllerConfiguration
public class MyReconciler implements Reconciler<MyCR> {
}
Thus, if a given resource was reconciled twice in one second, no further reconciliation for this resource will happen before two seconds have elapsed. Note that, since rate is limited on a per-resource basis, other resources can still be reconciled at the same time, as long, of course, that they stay within their own rate limits.
Handling Related Events with Event Sources
See also this blog post .
Event sources are a relatively simple yet powerful and extensible concept to trigger controller
executions, usually based on changes to dependent resources. You typically need an event source
when you want your Reconciler to be triggered when something occurs to secondary resources
that might affect the state of your primary resource. This is needed because a given
Reconciler will only listen by default to events affecting the primary resource type it is
configured for. Event sources act as listen to events affecting these secondary resources so
that a reconciliation of the associated primary resource can be triggered when needed. Note that
these secondary resources need not be Kubernetes resources. Typically, when dealing with
non-Kubernetes objects or services, we can extend our operator to handle webhooks or websockets
or to react to any event coming from a service we interact with. This allows for very efficient
controller implementations because reconciliations are then only triggered when something occurs
on resources affecting our primary resources thus doing away with the need to periodically
reschedule reconciliations.
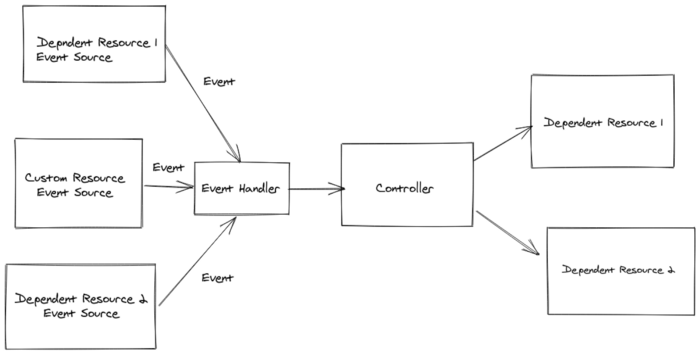
There are few interesting points here:
The CustomResourceEventSource event source is a special one, responsible for handling events
pertaining to changes affecting our primary resources. This EventSource is always registered
for every controller automatically by the SDK. It is important to note that events always relate
to a given primary resource. Concurrency is still handled for you, even in the presence of
EventSource implementations, and the SDK still guarantees that there is no concurrent execution of
the controller for any given primary resource (though, of course, concurrent/parallel executions
of events pertaining to other primary resources still occur as expected).
Caching and Event Sources
Kubernetes resources are handled in a declarative manner. The same also holds true for event
sources. For example, if we define an event source to watch for changes of a Kubernetes Deployment
object using an InformerEventSource, we always receive the whole associated object from the
Kubernetes API. This object might be needed at any point during our reconciliation process and
it’s best to retrieve it from the event source directly when possible instead of fetching it
from the Kubernetes API since the event source guarantees that it will provide the latest
version. Not only that, but many event source implementations also cache resources they handle
so that it’s possible to retrieve the latest version of resources without needing to make any
calls to the Kubernetes API, thus allowing for very efficient controller implementations.
Note after an operator starts, caches are already populated by the time the first reconciliation
is processed for the InformerEventSource implementation. However, this does not necessarily
hold true for all event source implementations (PerResourceEventSource for example). The SDK
provides methods to handle this situation elegantly, allowing you to check if an object is
cached, retrieving it from a provided supplier if not. See
related method
.
Registering Event Sources
To register event sources, your Reconciler has to override the prepareEventSources and return
list of event sources to register. One way to see this in action is
to look at the
tomcat example
(irrelevant details omitted):
@ControllerConfiguration
public class WebappReconciler
implements Reconciler<Webapp>, Cleaner<Webapp>, EventSourceInitializer<Webapp> {
// ommitted code
@Override
public Map<String, EventSource> prepareEventSources(EventSourceContext<Webapp> context) {
InformerEventSourceConfiguration<Tomcat> configuration =
InformerEventSourceConfiguration.from(Tomcat.class, Tomcat.class)
.withSecondaryToPrimaryMapper(webappsMatchingTomcatName)
.withPrimaryToSecondaryMapper(
(Webapp primary) -> Set.of(new ResourceID(primary.getSpec().getTomcat(),
primary.getMetadata().getNamespace())))
.build();
return EventSourceInitializer
.nameEventSources(new InformerEventSource<>(configuration, context));
}
}
In the example above an InformerEventSource is configured and registered.
InformerEventSource is one of the bundled EventSource implementations that JOSDK provides to
cover common use cases.
Managing Relation between Primary and Secondary Resources
Event sources let your operator know when a secondary resource has changed and that your
operator might need to reconcile this new information. However, in order to do so, the SDK needs
to somehow retrieve the primary resource associated with which ever secondary resource triggered
the event. In the Tomcat example above, when an event occurs on a tracked Deployment, the
SDK needs to be able to identify which Tomcat resource is impacted by that change.
Seasoned Kubernetes users already know one way to track this parent-child kind of relationship: using owner references. Indeed, that’s how the SDK deals with this situation by default as well, that is, if your controller properly set owner references on your secondary resources, the SDK will be able to follow that reference back to your primary resource automatically without you having to worry about it.
However, owner references cannot always be used as they are restricted to operating within a single namespace (i.e. you cannot have an owner reference to a resource in a different namespace) and are, by essence, limited to Kubernetes resources so you’re out of luck if your secondary resources live outside of a cluster.
This is why JOSDK provides the SecondayToPrimaryMapper interface so that you can provide
alternative ways for the SDK to identify which primary resource needs to be reconciled when
something occurs to your secondary resources. We even provide some of these alternatives in the
Mappers
class.
Note that, while a set of ResourceID is returned, this set usually consists only of one
element. It is however possible to return multiple values or even no value at all to cover some
rare corner cases. Returning an empty set means that the mapper considered the secondary
resource event as irrelevant and the SDK will thus not trigger a reconciliation of the primary
resource in that situation.
Adding a SecondaryToPrimaryMapper is typically sufficient when there is a one-to-many relationship
between primary and secondary resources. The secondary resources can be mapped to its primary
owner, and this is enough information to also get these secondary resources from the Context
object that’s passed to your Reconciler.
There are however cases when this isn’t sufficient and you need to provide an explicit mapping
between a primary resource and its associated secondary resources using an implementation of the
PrimaryToSecondaryMapper interface. This is typically needed when there are many-to-one or
many-to-many relationships between primary and secondary resources, e.g. when the primary resource
is referencing secondary resources.
See PrimaryToSecondaryIT
integration test for a sample.
Built-in EventSources
There are multiple event-sources provided out of the box, the following are some more central ones:
InformerEventSource
InformerEventSource
is probably the most important EventSource implementation to know about. When you create an
InformerEventSource, JOSDK will automatically create and register a SharedIndexInformer, a
fabric8 Kubernetes client class, that will listen for events associated with the resource type
you configured your InformerEventSource with. If you want to listen to Kubernetes resource
events, InformerEventSource is probably the only thing you need to use. It’s highly
configurable so you can tune it to your needs. Take a look at
InformerEventSourceConfiguration
and associated classes for more details but some interesting features we can mention here is the
ability to filter events so that you can only get notified for events you care about. A
particularly interesting feature of the InformerEventSource, as opposed to using your own
informer-based listening mechanism is that caches are particularly well optimized preventing
reconciliations from being triggered when not needed and allowing efficient operators to be written.
PerResourcePollingEventSource
PerResourcePollingEventSource is used to poll external APIs, which don’t support webhooks or other event notifications. It extends the abstract ExternalResourceCachingEventSource to support caching. See MySQL Schema sample for usage.
PollingEventSource
PollingEventSource
is similar to PerResourceCachingEventSource except that, contrary to that event source, it
doesn’t poll a specific API separately per resource, but periodically and independently of
actually observed primary resources.
Inbound event sources
SimpleInboundEventSource and CachingInboundEventSource are used to handle incoming events from webhooks and messaging systems.
ControllerResourceEventSource
ControllerResourceEventSource
is a special EventSource implementation that you will never have to deal with directly. It is,
however, at the core of the SDK is automatically added for you: this is the main event source
that listens for changes to your primary resources and triggers your Reconciler when needed.
It features smart caching and is really optimized to minimize Kubernetes API accesses and avoid
triggering unduly your Reconciler.
More on the philosophy of the non Kubernetes API related event source see in issue #729.
Contextual Info for Logging with MDC
Logging is enhanced with additional contextual information using MDC. The following attributes are available in most parts of reconciliation logic and during the execution of the controller:
| MDC Key | Value added from primary resource |
|---|---|
resource.apiVersion | .apiVersion |
resource.kind | .kind |
resource.name | .metadata.name |
resource.namespace | .metadata.namespace |
resource.resourceVersion | .metadata.resourceVersion |
resource.generation | .metadata.generation |
resource.uid | .metadata.uid |
For more information about MDC see this link.
InformerEventSource Multi-Cluster Support
It is possible to handle resources for remote cluster with InformerEventSource. To do so,
simply set a client that connects to a remote cluster:
InformerEventSourceConfiguration<Tomcat> configuration =
InformerEventSourceConfiguration.from(SecondaryResource.class, PrimaryResource.class)
.withKubernetesClient(remoteClusterClient)
.withSecondaryToPrimaryMapper(Mappers.fromDefaultAnnotations());
You will also need to specify a SecondaryToPrimaryMapper, since the default one
is based on owner references and won’t work across cluster instances. You could, for example, use the provided implementation that relies on annotations added to the secondary resources to identify the associated primary resource.
See related integration test.
Dynamically Changing Target Namespaces
A controller can be configured to watch a specific set of namespaces in addition of the
namespace in which it is currently deployed or the whole cluster. The framework supports
dynamically changing the list of these namespaces while the operator is running.
When a reconciler is registered, an instance of
RegisteredController
is returned, providing access to the methods allowing users to change watched namespaces as the
operator is running.
A typical scenario would probably involve extracting the list of target namespaces from a
ConfigMap or some other input but this part is out of the scope of the framework since this is
use-case specific. For example, reacting to changes to a ConfigMap would probably involve
registering an associated Informer and then calling the changeNamespaces method on
RegisteredController.
public static void main(String[] args) {
KubernetesClient client = new DefaultKubernetesClient();
Operator operator = new Operator(client);
RegisteredController registeredController = operator.register(new WebPageReconciler(client));
operator.installShutdownHook();
operator.start();
// call registeredController further while operator is running
}
If watched namespaces change for a controller, it might be desirable to propagate these changes to
InformerEventSources associated with the controller. In order to express this,
InformerEventSource implementations interested in following such changes need to be
configured appropriately so that the followControllerNamespaceChanges method returns true:
@ControllerConfiguration
public class MyReconciler implements Reconciler<TestCustomResource> {
@Override
public Map<String, EventSource> prepareEventSources(
EventSourceContext<ChangeNamespaceTestCustomResource> context) {
InformerEventSource<ConfigMap, TestCustomResource> configMapES =
new InformerEventSource<>(InformerEventSourceConfiguration.from(ConfigMap.class, TestCustomResource.class)
.withNamespacesInheritedFromController(context)
.build(), context);
return EventSourceUtils.nameEventSources(configMapES);
}
}
As seen in the above code snippet, the informer will have the initial namespaces inherited from controller, but also will adjust the target namespaces if it changes for the controller.
See also the integration test for this feature.
Leader Election
Operators are generally deployed with a single running or active instance. However, it is possible to deploy multiple instances in such a way that only one, called the “leader”, processes the events. This is achieved via a mechanism called “leader election”. While all the instances are running, and even start their event sources to populate the caches, only the leader will process the events. This means that should the leader change for any reason, for example because it crashed, the other instances are already warmed up and ready to pick up where the previous leader left off should one of them become elected leader.
See sample configuration in the E2E test .
Runtime Info
RuntimeInfo is used mainly to check the actual health of event sources. Based on this information it is easy to implement custom liveness probes.
stopOnInformerErrorDuringStartup setting, where this flag usually needs to be set to false, in order to control the exact liveness properties.
See also an example implementation in the WebPage sample
Automatic Generation of CRDs
Note that this feature is provided by the Fabric8 Kubernetes Client, not JOSDK itself.
To automatically generate CRD manifests from your annotated Custom Resource classes, you only need to add the following dependencies to your project:
<dependency>
<groupId>io.fabric8</groupId>
<artifactId>crd-generator-apt</artifactId>
<scope>provided</scope>
</dependency>
The CRD will be generated in target/classes/META-INF/fabric8 (or
in target/test-classes/META-INF/fabric8, if you use the test scope) with the CRD name
suffixed by the generated spec version. For example, a CR using the java-operator-sdk.io group
with a mycrs plural form will result in 2 files:
mycrs.java-operator-sdk.io-v1.ymlmycrs.java-operator-sdk.io-v1beta1.yml
NOTE:
Quarkus users using the
quarkus-operator-sdkextension do not need to add any extra dependency to get their CRD generated as this is handled by the extension itself.
Metrics
JOSDK provides built-in support for metrics reporting on what is happening with your reconcilers in the form of
the Metrics interface which can be implemented to connect to your metrics provider of choice, JOSDK calling the
methods as it goes about reconciling resources. By default, a no-operation implementation is provided thus providing a
no-cost sane default. A micrometer-based implementation is also provided.
You can use a different implementation by overriding the default one provided by the default ConfigurationService, as
follows:
Metrics metrics; // initialize your metrics implementation
Operator operator = new Operator(client, o -> o.withMetrics(metrics));
Micrometer implementation
The micrometer implementation is typically created using one of the provided factory methods which, depending on which is used, will return either a ready to use instance or a builder allowing users to customized how the implementation behaves, in particular when it comes to the granularity of collected metrics. It is, for example, possible to collect metrics on a per-resource basis via tags that are associated with meters. This is the default, historical behavior but this will change in a future version of JOSDK because this dramatically increases the cardinality of metrics, which could lead to performance issues.
To create a MicrometerMetrics implementation that behaves how it has historically behaved, you can just create an
instance via:
MeterRegistry registry; // initialize your registry implementation
Metrics metrics = new MicrometerMetrics(registry);
Note, however, that this constructor is deprecated and we encourage you to use the factory methods instead, which either return a fully pre-configured instance or a builder object that will allow you to configure more easily how the instance will behave. You can, for example, configure whether or not the implementation should collect metrics on a per-resource basis, whether or not associated meters should be removed when a resource is deleted and how the clean-up is performed. See the relevant classes documentation for more details.
For example, the following will create a MicrometerMetrics instance configured to collect metrics on a per-resource
basis, deleting the associated meters after 5 seconds when a resource is deleted, using up to 2 threads to do so.
MicrometerMetrics.newPerResourceCollectingMicrometerMetricsBuilder(registry)
.withCleanUpDelayInSeconds(5)
.withCleaningThreadNumber(2)
.build();
Operator SDK metrics
The micrometer implementation records the following metrics:
| Meter name | Type | Tag names | Description |
|---|---|---|---|
operator.sdk.reconciliations.executions.<reconciler name> | gauge | group, version, kind | Number of executions of the named reconciler |
operator.sdk.reconciliations.queue.size.<reconciler name> | gauge | group, version, kind | How many resources are queued to get reconciled by named reconciler |
operator.sdk.<map name>.size | gauge map size | Gauge tracking the size of a specified map (currently unused but could be used to monitor caches size) | |
| operator.sdk.events.received | counter | <resource metadata>, event, action | Number of received Kubernetes events |
| operator.sdk.events.delete | counter | <resource metadata> | Number of received Kubernetes delete events |
| operator.sdk.reconciliations.started | counter | <resource metadata>, reconciliations.retries.last, reconciliations.retries.number | Number of started reconciliations per resource type |
| operator.sdk.reconciliations.failed | counter | <resource metadata>, exception | Number of failed reconciliations per resource type |
| operator.sdk.reconciliations.success | counter | <resource metadata> | Number of successful reconciliations per resource type |
| operator.sdk.controllers.execution.reconcile | timer | <resource metadata>, controller | Time taken for reconciliations per controller |
| operator.sdk.controllers.execution.cleanup | timer | <resource metadata>, controller | Time taken for cleanups per controller |
| operator.sdk.controllers.execution.reconcile.success | counter | controller, type | Number of successful reconciliations per controller |
| operator.sdk.controllers.execution.reconcile.failure | counter | controller, exception | Number of failed reconciliations per controller |
| operator.sdk.controllers.execution.cleanup.success | counter | controller, type | Number of successful cleanups per controller |
| operator.sdk.controllers.execution.cleanup.failure | counter | controller, exception | Number of failed cleanups per controller |
As you can see all the recorded metrics start with the operator.sdk prefix. <resource metadata>, in the table above,
refers to resource-specific metadata and depends on the considered metric and how the implementation is configured and
could be summed up as follows: group?, version, kind, [name, namespace?], scope where the tags in square
brackets ([]) won’t be present when per-resource collection is disabled and tags followed by a question mark are
omitted if the associated value is empty. Of note, when in the context of controllers’ execution metrics, these tag
names are prefixed with resource.. This prefix might be removed in a future version for greater consistency.
Optimizing Caches
One of the ideas around the operator pattern is that all the relevant resources are cached, thus reconciliation is usually very fast (especially if no resources are updated in the process) since the operator is then mostly working with in-memory state. However for large clusters, caching huge amount of primary and secondary resources might consume lots of memory. JOSDK provides ways to mitigate this issue and optimize the memory usage of controllers. While these features are working and tested, we need feedback from real production usage.
Bounded Caches for Informers
Limiting caches for informers - thus for Kubernetes resources - is supported by ensuring that resources are in the cache for a limited time, via a cache eviction of least recently used resources. This means that when resources are created and frequently reconciled, they stay “hot” in the cache. However, if, over time, a given resource “cools” down, i.e. it becomes less and less used to the point that it might not be reconciled anymore, it will eventually get evicted from the cache to free up memory. If such an evicted resource were to become reconciled again, the bounded cache implementation would then fetch it from the API server and the “hot/cold” cycle would start anew.
Since all resources need to be reconciled when a controller start, it is not practical to set a maximal cache size as it’s desirable that all resources be cached as soon as possible to make the initial reconciliation process on start as fast and efficient as possible, avoiding undue load on the API server. It’s therefore more interesting to gradually evict cold resources than try to limit cache sizes.
See usage of the related implementation using Caffeine cache in integration tests for primary resources.
See also CaffeineBoundedItemStores for more details.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.